[技术向] CSAPP (深入理解计算机系统) 虚拟内存
虚拟内存 (VM) 是一个 kernel 程序, 提供了存储的顶层抽象, 将主内存视作硬盘的缓存进行管理.
好处:
实现了硬件异常处理、硬件地址转换、主内存和硬盘之间的优雅交互.
为每个进程 (P) 提供一个统一、 私有的地址空间 (虚拟地址空间), 保护每个 P 的内存操作互不干扰.
物理/虚拟地址
主内存可以看作一条长度为 M 的字节数组, 每个字节都有一个物理地址 (0, 1, 2, ..., M-1). 早期的计算机系统中, CPU 直接采用物理地址与 M 交互, 如今则是采用虚拟地址. 虚拟地址向物理地址的转换由 CPU 中的内存管理单元 (MMU) 与 OS 合作完成 (软硬件协同).
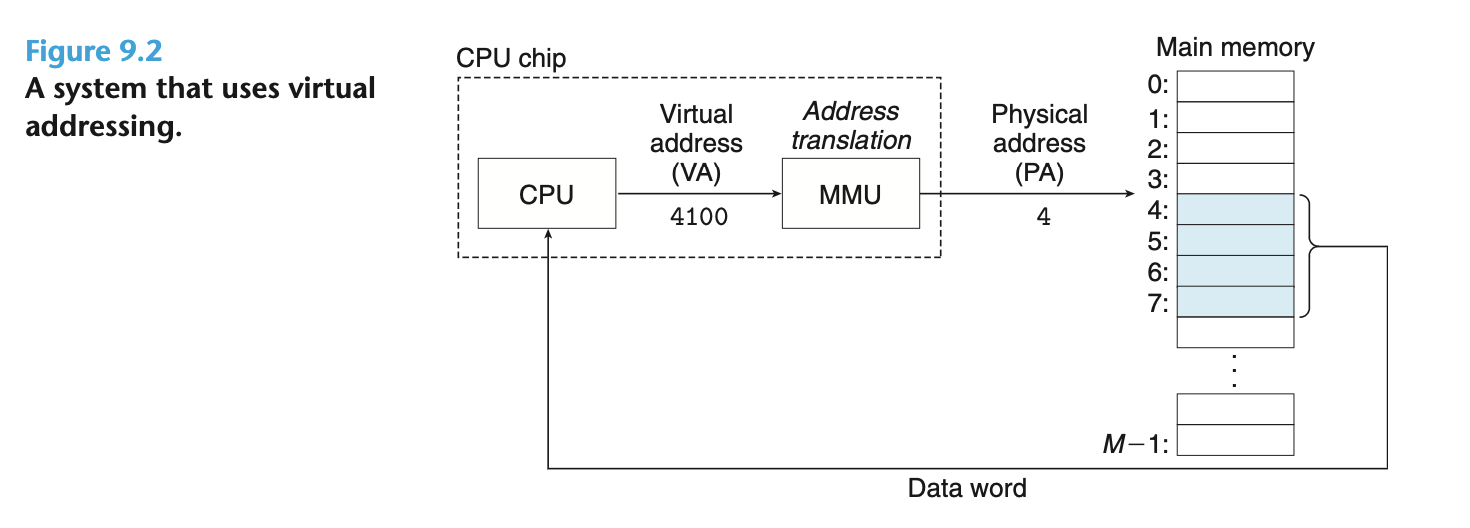
虚拟内存的作用
按照 存储层次结构 中的描述, "M - Disk"这一层缓存关系是借助 VM 实现的.
VM 将虚拟地址空间划分成许多固定大小的块, 称作"虚拟页", 将物理地址空间也进行这样的划分, 称作"物理页"或"页帧". 虚拟页和物理页的大小相同.
虚拟页有 3 种状态: 1) 未分配, 2) 已缓存, 3) 未缓存.

磁盘连续读取是比较划算的, 因此虚拟页不宜过小, 一般取 4KB ~ 2MB (也不是越大越好, 因为虚拟内存的优越性更多还是依赖于程序的时间局部性, 即一个时间段内相同的地址会被反复访问). 又考虑到 Disk 访问速度比 DRAM 慢了约 6 个数量级 (SSD 是 1~3 个数量级), 寻页失败 (page fault) 的代价是非常高的, 因此 VM 通常使用全关联映射和回写策略, 采取的缓存替换算法也比较复杂.
OS 通过在 M 中维护页表 (Page Table), 来实现上述缓存机制. 每个进程都有自己的页表.

PT 条目 (Entry) 的大小是固定的, 因此 MMU 可以直接将虚拟地址转换成 PTE 的 idx, 再结合 PT 的起始地址 (从寄存器获取) 进行查询. 若标记有效则直接读取 M 中的数据, 否则会产生 page fault, 调起相应的 kernel 异常处理程序, 替换物理页.
每个 P 的虚拟地址空间是独立的, 但可以共享物理页面 (比如父进程 fork 出子进程), 配合写时复制 (COW) 策略.

内存管理
VM 如何简化内存管理 ?
[ 链接 ] 根据 异常控制流 中的描述, Linux 进程都有基本一致的内存格式. 比如, 对于 64 位地址空间, P 的代码段 (code segment) 都是从
0x400000开始, 随后是数据段, 栈区则是从高位地址向低位地址增长. 这种一致性可以简化链接器的实现.[ 装载 ] 物理页按需 (on-demand) 加载到内存.
[ 共享] 只读的物理页可以在不同进程之间共享.
[ 内存分配 ] 当 P 向 OS 申请新的内存空间时, 分配虚拟页, 将实际的物理内存分配延后.
内存保护
VM 如何进行内存保护 ?
当 P 对 M 的访问违反了下述页表所示的规则时, 会产生 Segment Fault.
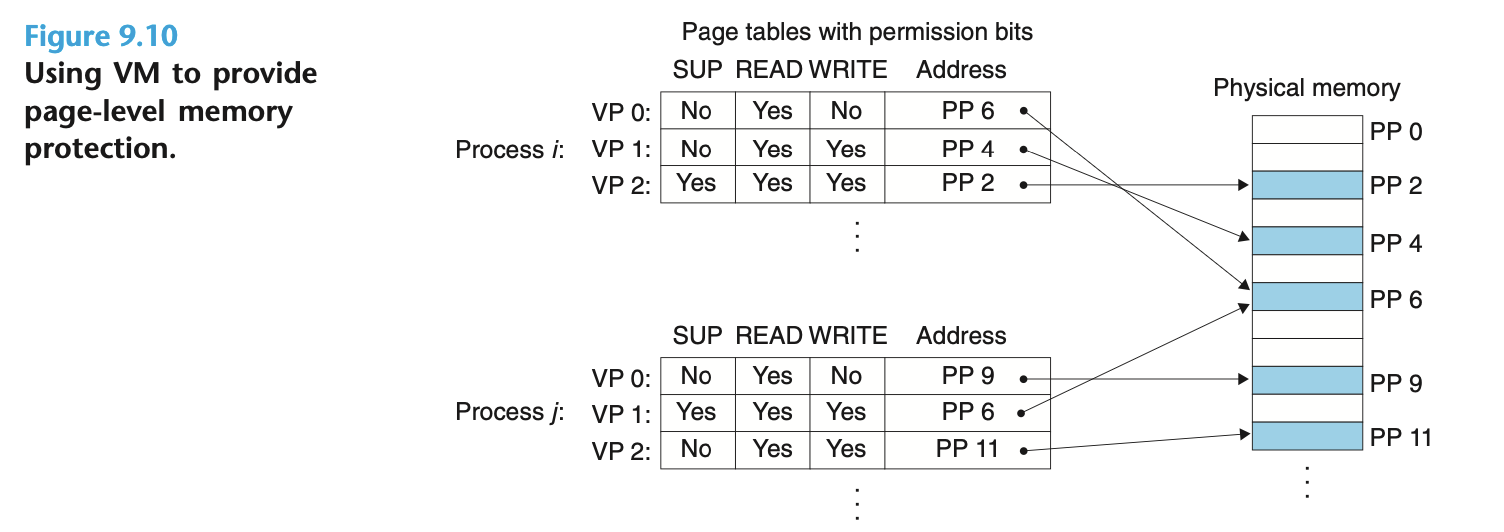
这一检查是在地址转换的过程中进行的.
操作系统的虚拟地址空间有一部分属于内核空间, 被各个进程共享, 存放中断程序等数据.
内存映射与分配
虚拟地址转换成物理地址的过程:
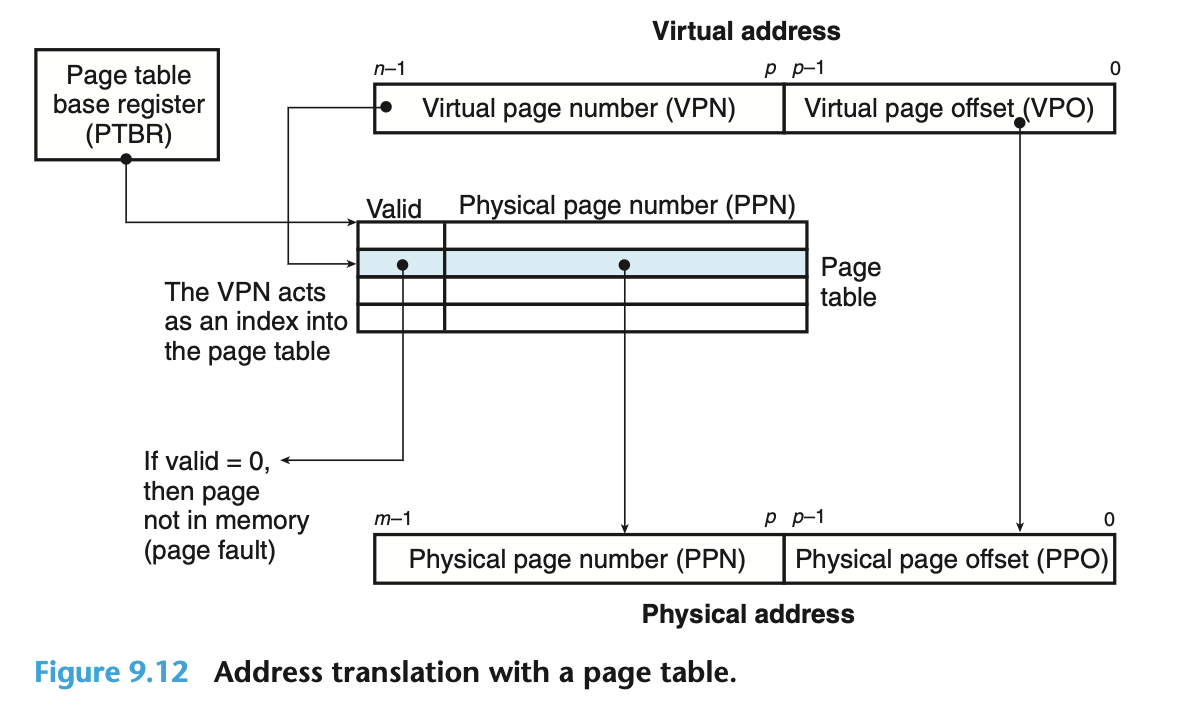
CPU 产生一个虚拟地址, 传给 MMU
MMU 首先得到 PTE 的地址, 向 M 发起查询
M 返回 PTE
若 PTE 有效标记为 1 , MMU 构建得到物理地址, 向 M 发起第二次查询
M 将指定地址的数据返回给 CPU

若 PTE 有效标记为 0 , MMU 会触发 page fault, 将 CPU 控制权转移给 kernel 的缺页异常处理器 H
H 先确定 M 中的换出页, 若被修改过, 要回写
H 从 Disk 读取新的一页到 M, 并更新 PTE
返回到原进程, CPU 重新将虚拟地址传给 MMU (步骤 1)
大部分系统在访问 SRAM 时仍然用物理地址.
为了加快地址转换, 许多系统会在 MMU 中集成转换后备缓冲器 (TLB, translation look-aside buffer), 用于缓存 PTE.
TBL 存储 <虚页号, PTE> 映射.

P 切换时也要切换页表, 导致 TLB 的信息失效, 这是 P 切换的开销要大于线程的主要原因之一.
多级页表
32 位的地址空间 (4 GB), 一个页 4 KB, 一个 PTE (32 / 8 =) 4B >>> PT 大小: (2^32 / 2^12 × 4 =) 4 MB
64 位的地址空间 (16 EB), 一个 PTE (64 / 8 =) 8B >>> PT 大小: (2^64 / 2^12 × 8 =) 32 PB
采用二级 PT, 则 32 位地址空间需要的 PT 大小: (√(2^32 / 2^12) × 4 =) 4 KB
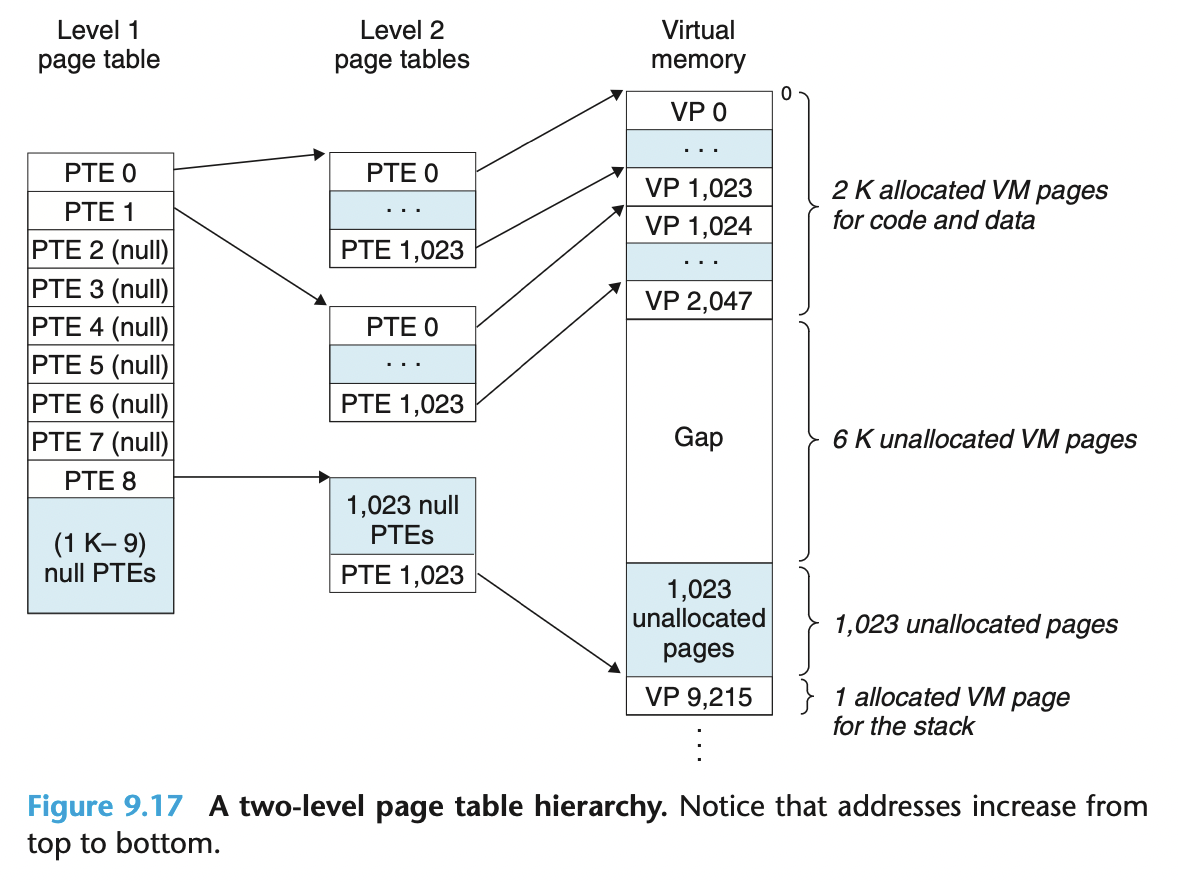
一个 k 级 PT 系统中, 地址转换的过程如下:
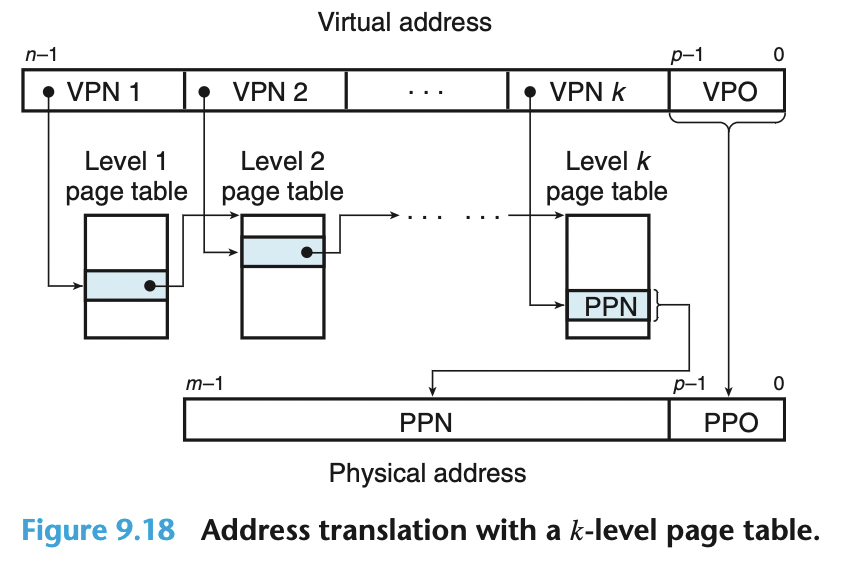
实例
运行在 Intel Core i7 上的 Linux 支持 48 位虚拟地址空间, 52 位物理地址空间, 采用 4 级 PT:

一个 P 的 VM 结构:
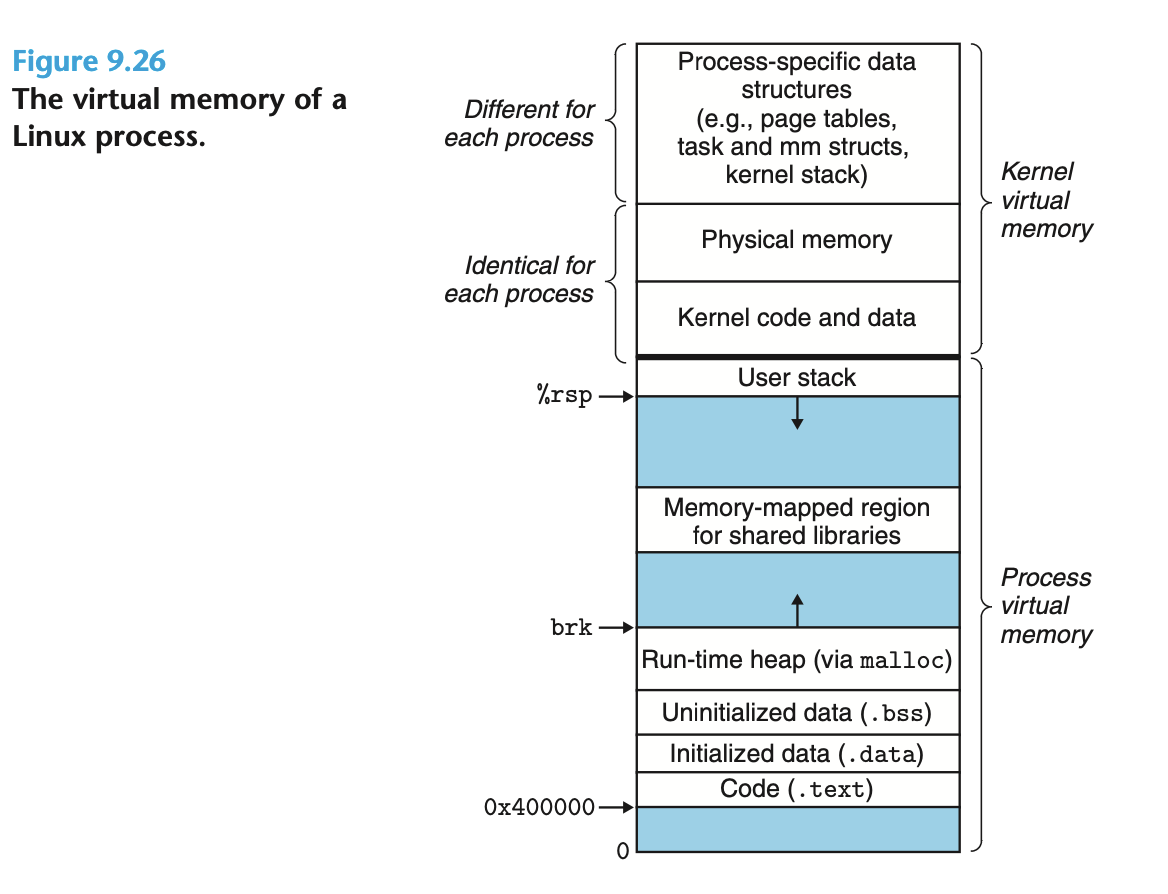
内存分配
Linux 对 VM 的初始化过程, 就是建立 VM 区域与磁盘的关联, 这个过程又叫内存映射.
以 mmap 为例, 有两种类型的映射对象:
[ 常规文件 ] 一般来说是连续编号的磁盘扇区, 有数据.
[ 匿名文件 ] 可理解为只是单纯向 kernel 申请一块内存暂用, 只需将分配的物理页 reset zero, 不需要读磁盘.
动态内存分配
所谓动态是指, 在 P 运行期间为其分配不定的内存空间.
一个动态内存分配器维护着对应 P 的虚拟内存的堆空间 (通过 brk 指针访问), 堆空间被划分成多种大小的块 (block), 其头部包含一些元信息.
用户程序所使用的指针, 实际指向的是块的有效负载 (payload) 部分.
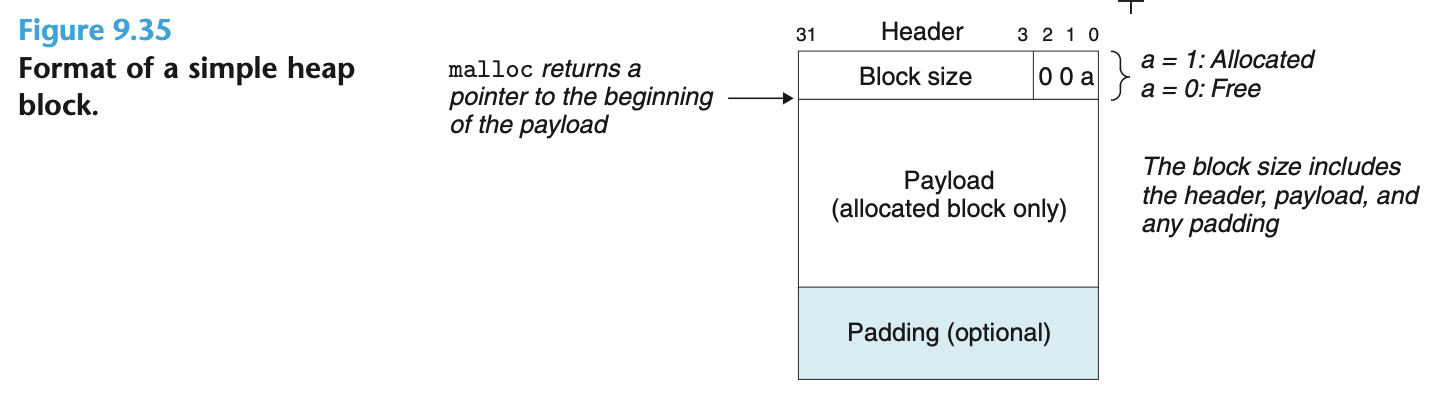
分配过程会产生内部碎片和外部碎片. 对空闲链表的管理是最关键的部分.
垃圾回收
垃圾回收 (Garbage Collect) 指的是释放进程不再需要的内存.
GC 可达性分析
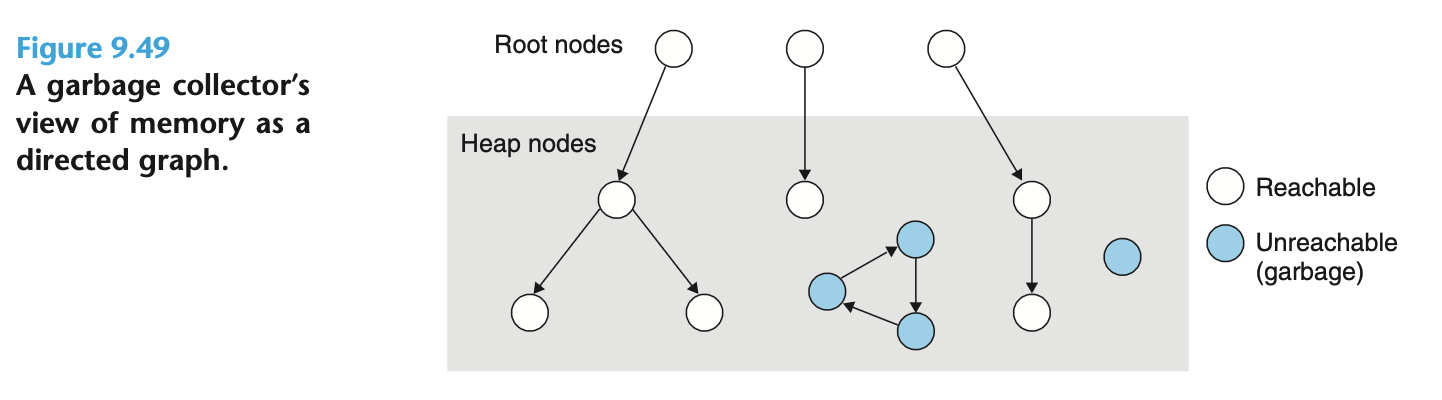
在回收器的视角里, M 是一个有向图, 图中的节点分为根节点和堆节点.
堆节点指的是在堆上已分配的 block, 根节点则是不在堆上的变量, 但包含指针指向堆节点, 比如栈上的变量, 虚存中的全局变量.
回收器的任务是维护这张图的可达性表示, 并定期释放不可达的节点.
类似 Java 这种将指针的创建和使用都纳入虚拟机管理范畴的语言, 回收器可以做到准确的可达性分析. 像 C/C++ 则不行, 内存中的数据没有包含类型信息, int 也可以当作指针使用 (赋值给指针), 因此一些不可达的节点有时会被误判为可达. 我们称这种情况下的回收器是保留性 (conservative) 的.
标记-清除算法
[ 标记 ] 从根节点开始, 以某种顺序, 常见如 DFS/BFS, 遍历所有可达的节点并做标记.
[ 清除 ] 遍历堆中的 block, 遇到未标记的就释放掉.
对于数据不包含类型信息的情况, 一种解决方案是在 block 的头部中加入 left, right 两个字段, 将已分配的块组成一棵平衡二叉树, 从而执行 binary search, 快速判断某个值 p 是否指向一个已分配的 block.
但是, p 可能在程序中是一个 int, 但其值恰好等于某个 block 的 payload 中的地址, 因此这种方案只能保证不会释放掉可达的节点, 但有可能保留一些不可达的节点.
补充
malloc 函数的原理?
malloc 向 kernel 申请 M (拓展堆的上界) 有两种方式:
brk()/sbrk(): 分别以brk指针作为入参/返回值, 申请小内存时使用.mmap: 匿名文件, 申请大内存时使用.
malloc 只是申请到了虚拟内存, 还没有建立映射, 当访问出现 page fault 时才会分配物理内存. 这种设计本质上是一种懒加载.