[技术向] CSAPP (深入理解计算机系统) 存储层次结构
从 CPU 的角度看, 内存被抽象成一条字节阵列, 实际上内存系统是具有层次结构的, 不同层次的设备具有不同的容量, 速度和成本. 这种层次结构之所以有效, 是因为编写良好的程序在某一时间段内, 对存储在高层次设备的数据的访问频率总是相对较高 (局部性). 当然, 为了更有效地利用这个特性, 还需要 OS 提供恰当的缓存策略.
存储技术
随机访问内存 (RAM)
SRAM (贵, 快, 稳定, 较多用于 Cache) vs. DRAM (不稳定, 需要不断刷新, 较多用于内存)

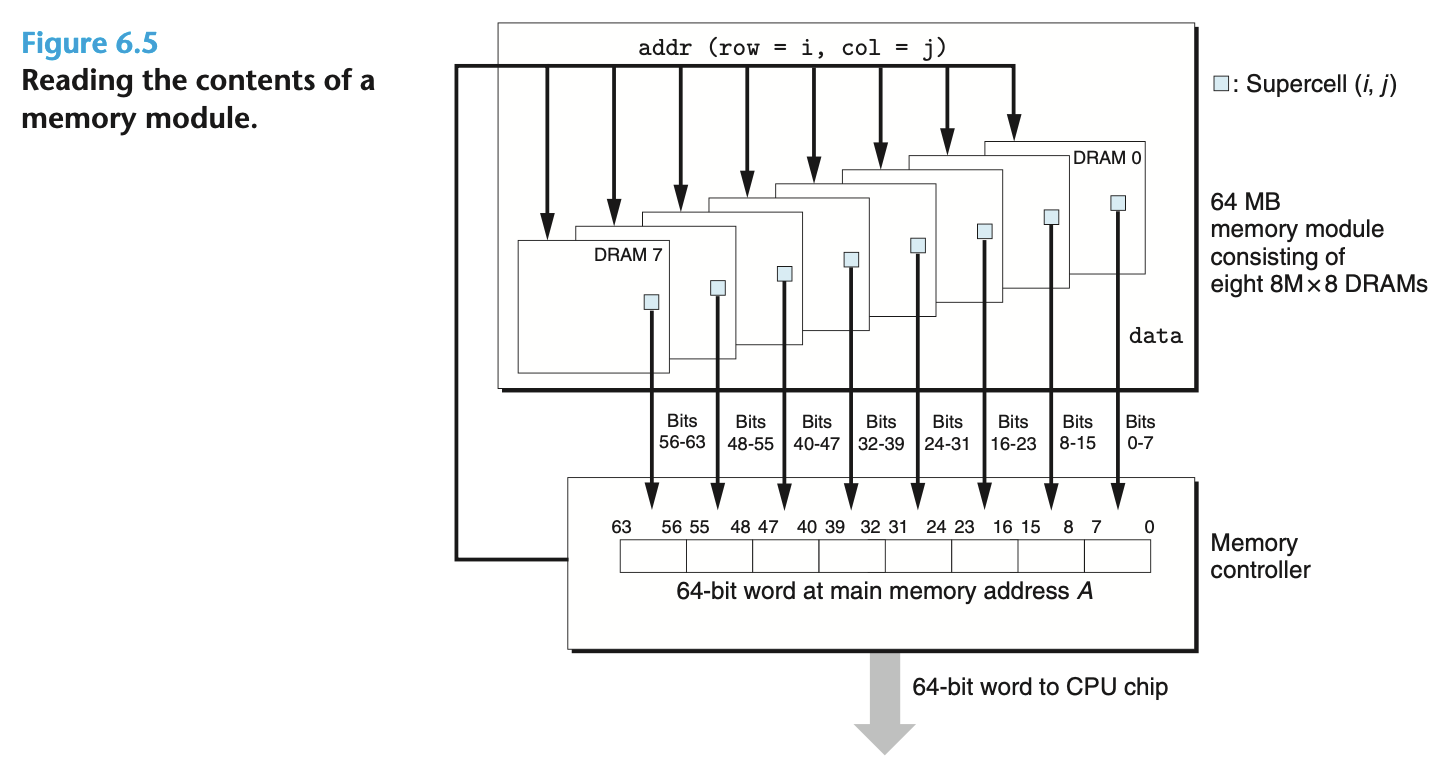
内存模块说的是多个 DRAM 的组合, 例如, 8 个 8M 的 DRAM 组成了 64M 的内存, 每次读写的数据实际上是由 8 个单元共同拼接起来的:
磁盘存储
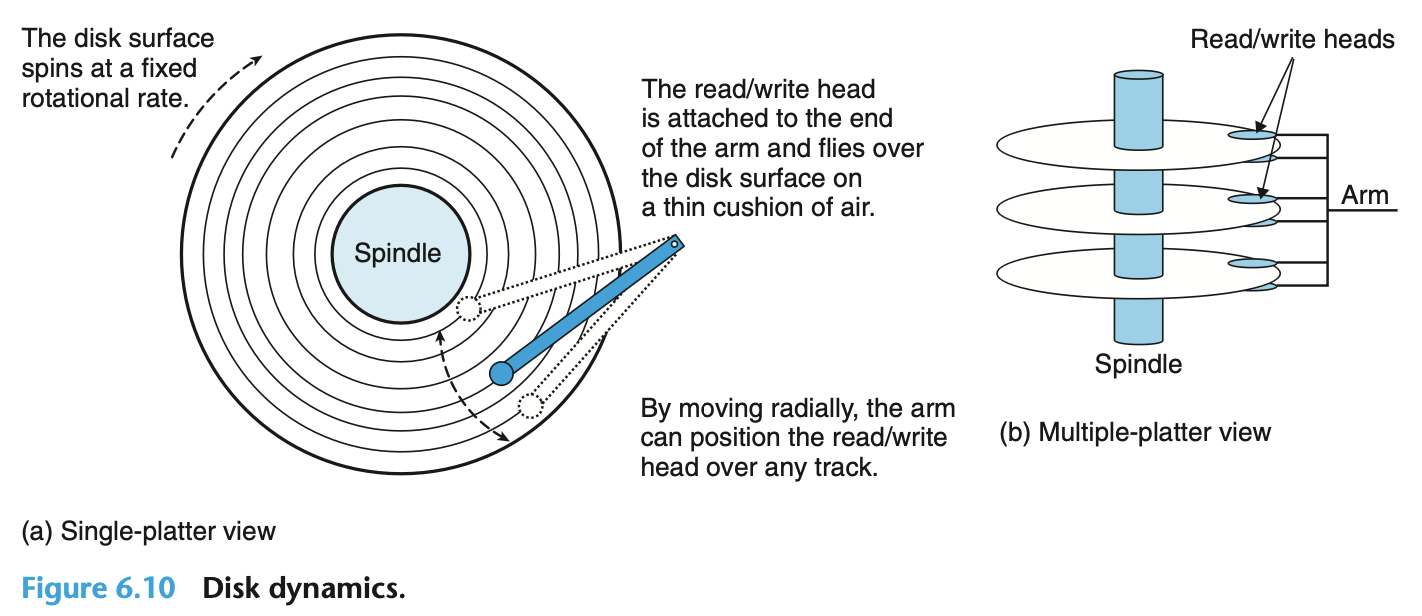
磁盘结构和读写操作:
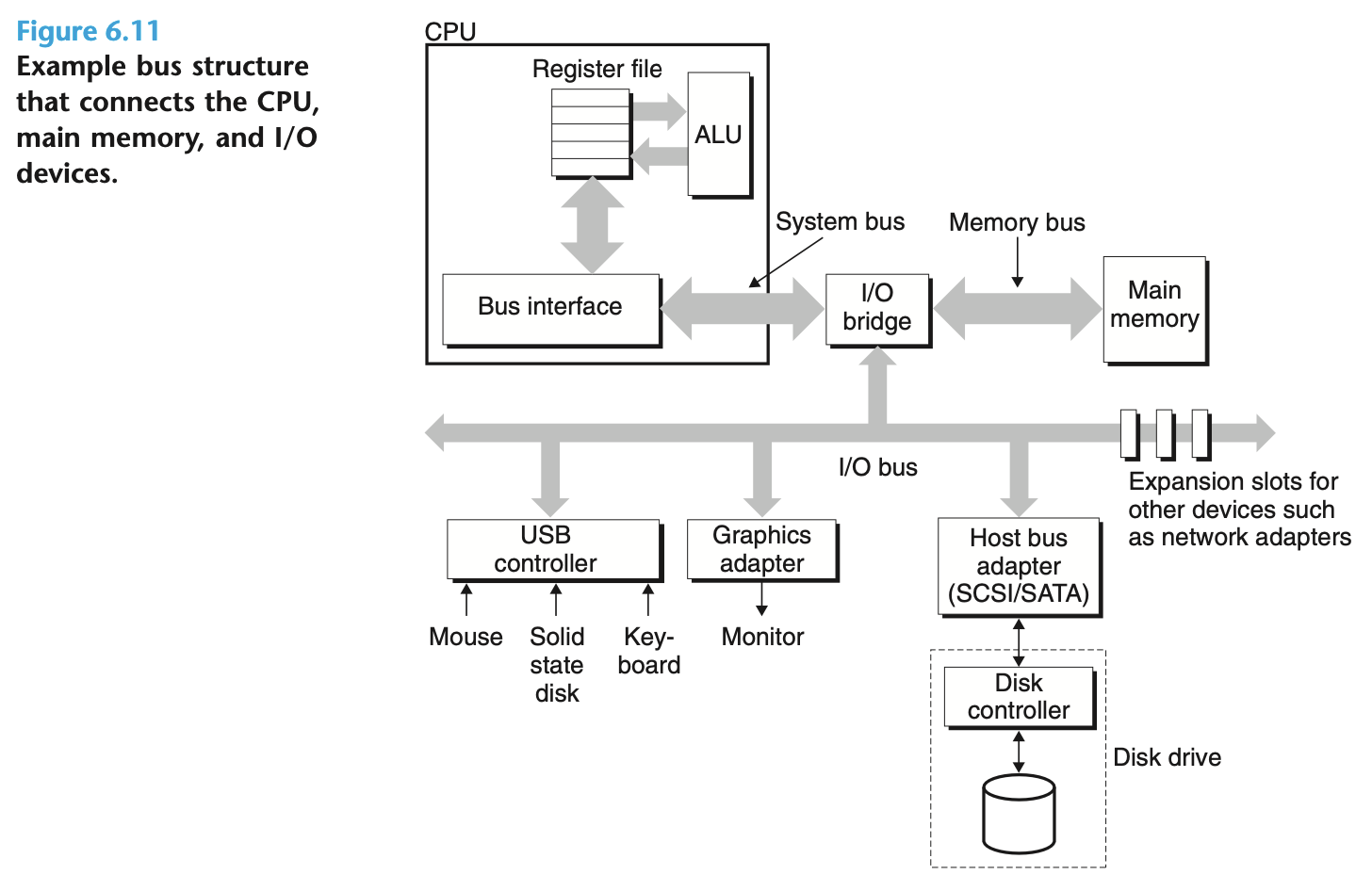
从系统的角度看, I/O 设备通过 bus 连接, 再通过 I/O bridge 与 CPU 和内存进行数据传输:
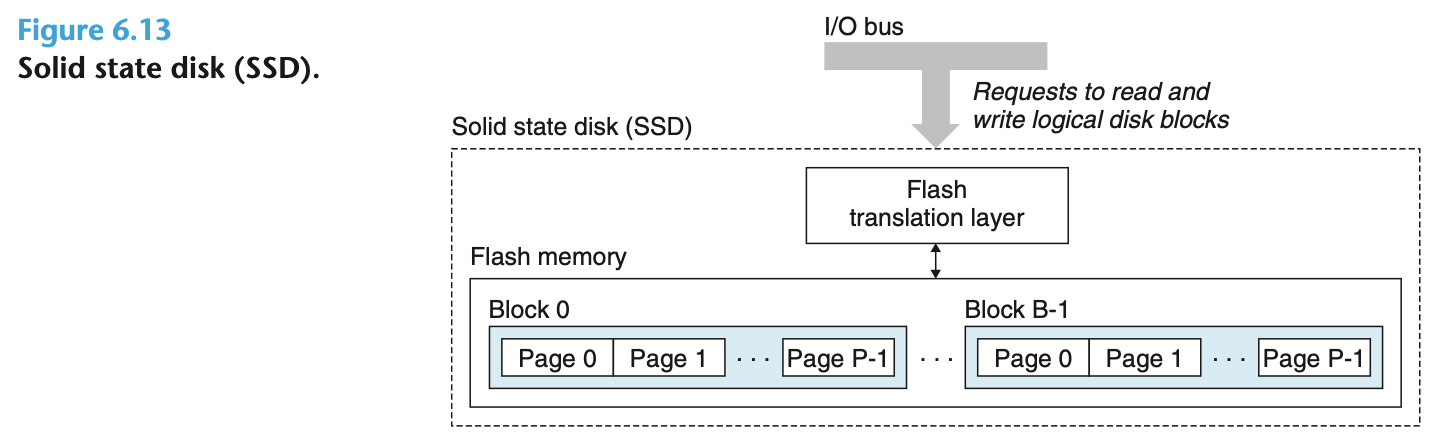
固态硬盘 (SSD / Flash):
层次结构
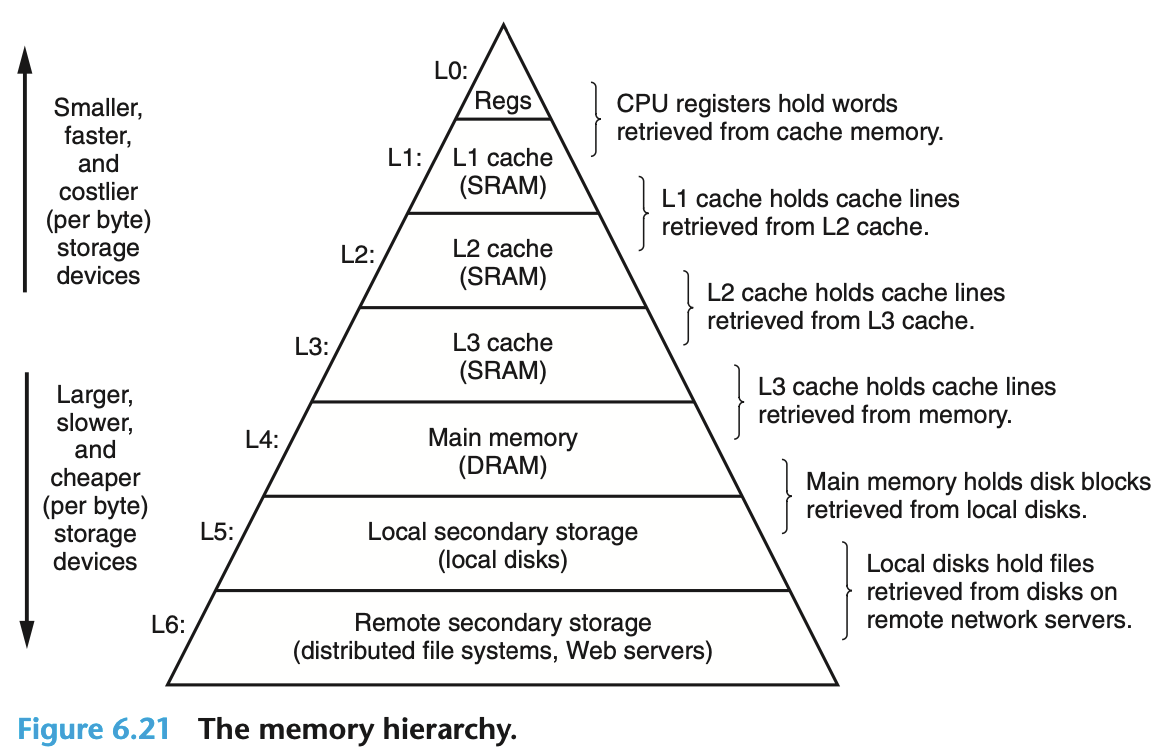
寄存器 - L1/L2/L3 Cache (SRAM) - 主内存 (DRAM) - 本地磁盘/SSD - 网络存储
缓存即是将存储在容量较大但速度较慢的设备上的数据, 暂时存放在容量较小但速度较快的设备上.
存储层级的本质是让较高一层 (更靠近 CPU) 的设备作为较低一层的设备的缓存. 这一方面直接体现在硬件组织上, 另一方面, 程序也会尽可能利用局部性规律 (空间和时间).
内存缓存
早期的计算机存储层级只由寄存器, 主内存和硬盘组成. 随着 CPU 计算速度的增加, 用作主内存的 DRAM 已匹配不上, 因此发展出了 SRAM 用作内存的缓存, 即 L1, L2, L3...
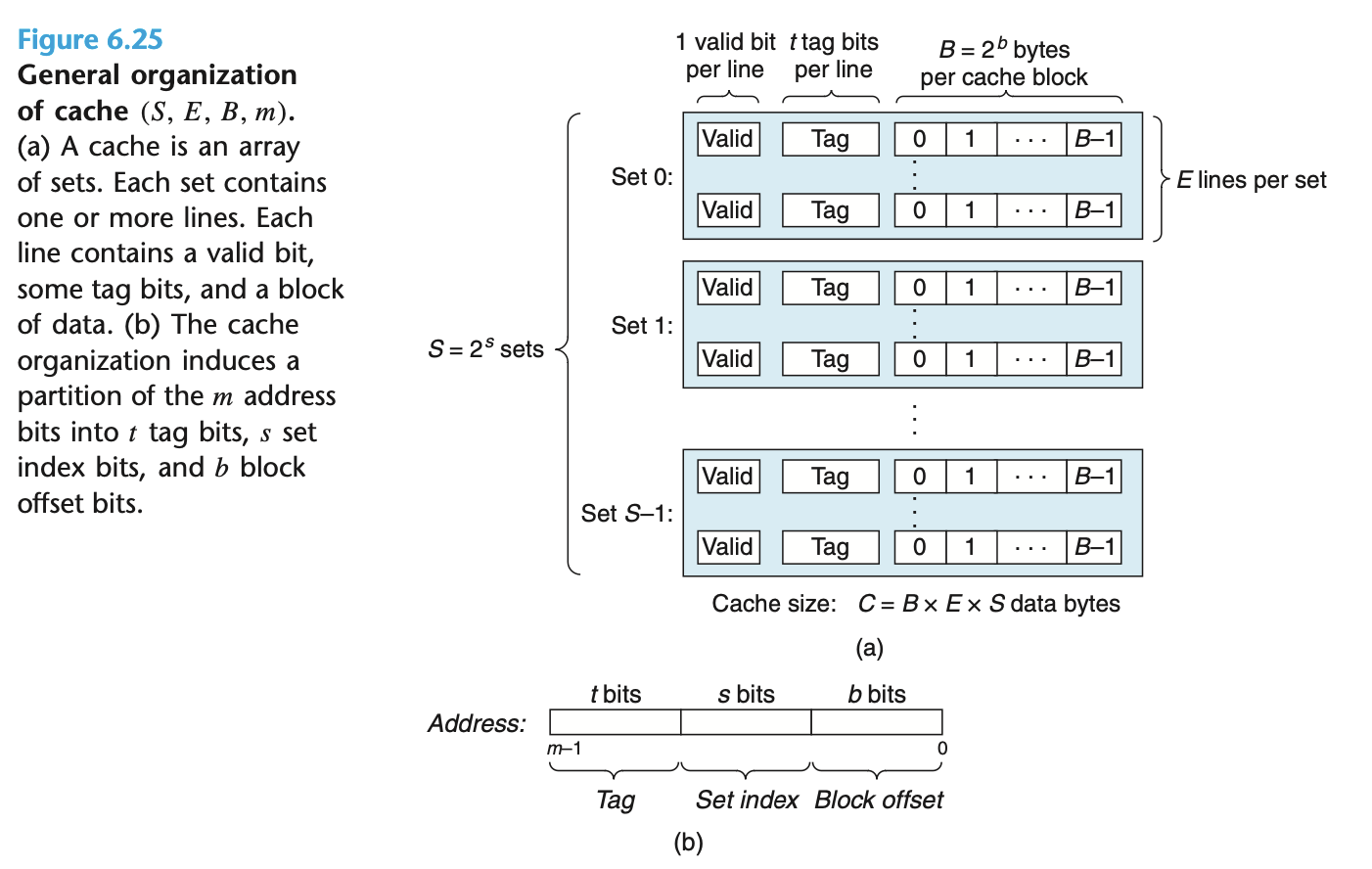
通用的多路关联内存缓存结构如下. 一个 Set 可以包含多个缓存行, 一行对应一个缓存数据块 (2^b 字节). 内存地址中间的 s 个 bits 决定此处的数据应该被缓存在哪个 Set (一共有 2^s 个 Set), 高位的 t 个 bits 则用作同一个 Set 内部的标识. 用中间的 bits 作为 Set 索引, 是为了充分利用程序的空间局部性, 若改用高位作索引, 则后续的 2^t 个内存块会被映射到同一个 Set, 空间局部性被没有被利用起来.
在总缓存空间固定的情况下, b 的大小选择反映了对空间和时间局部性的权衡. b 取值越大, 一个缓存行可以包含的内存数据越多, 这些数据在内存里是连续的, 也就意味着越倾向于空间局部性.
查询缓存的方式:
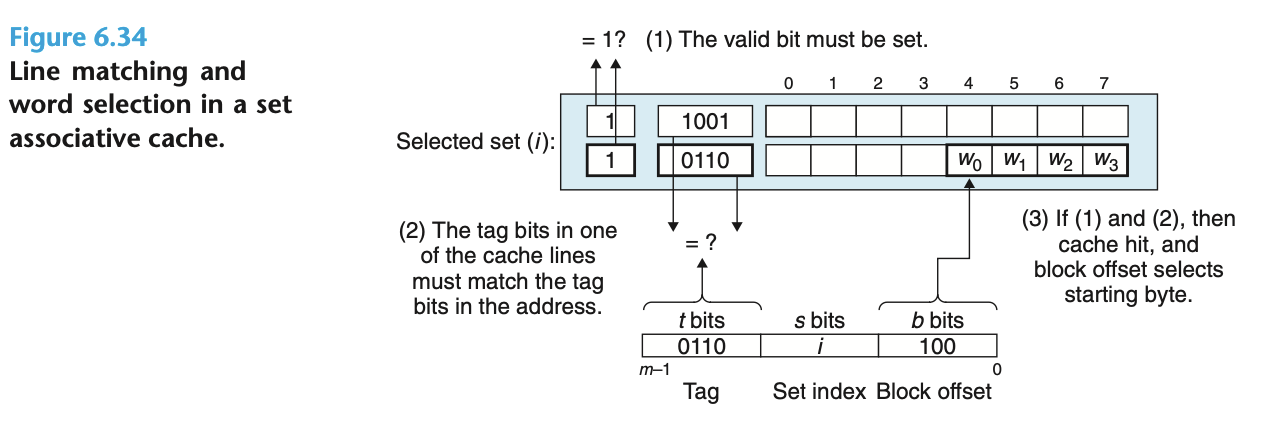
根据内存地址中间的 s 个 bits 确定 Cache Set, 根据高位的 t 个 bits 确定内部的缓存行
检查缓存行是否有效
若缓存命中, 就可以根据低位的偏移量从缓存行里取出对应的字节
上述内存结构是一种通用方案 (多路关联映射), 可以派生出两种特殊情况:
直接映射: 每个 Set 只包含一个缓存行
全关联映射: 不区分 Set 和 Tag
全关联映射的好处是, 下层设备任意位置的数据可以缓存在上层设备的任意位置, 总体将拥有更高的命中率. 当缓存缺失的代价较高时可采用此方案.
写操作
当程序要写的记录已经在缓存中, 有两种方案可供选择:
直接写: 更新缓存的同时也更新下层设备的数据, 简单, 但是对总线的访问比较频繁
回写: 只更新缓存, 等被驱逐时才更新下层设备的数据, 需要一个 dirty 标识位
对应地, 若要写的记录不在缓存中:
非写分配: 只更新下层设备的数据, 不更新缓存
写分配: 同步更新缓存和下层设备
回写 & 写分配的组合能更好利用局部性 (否则, 若多次写一条原本不在缓存中的记录, 则每次写都要访问下层设备). 对现代的系统而言, 实现这种组合并不困难.
实例
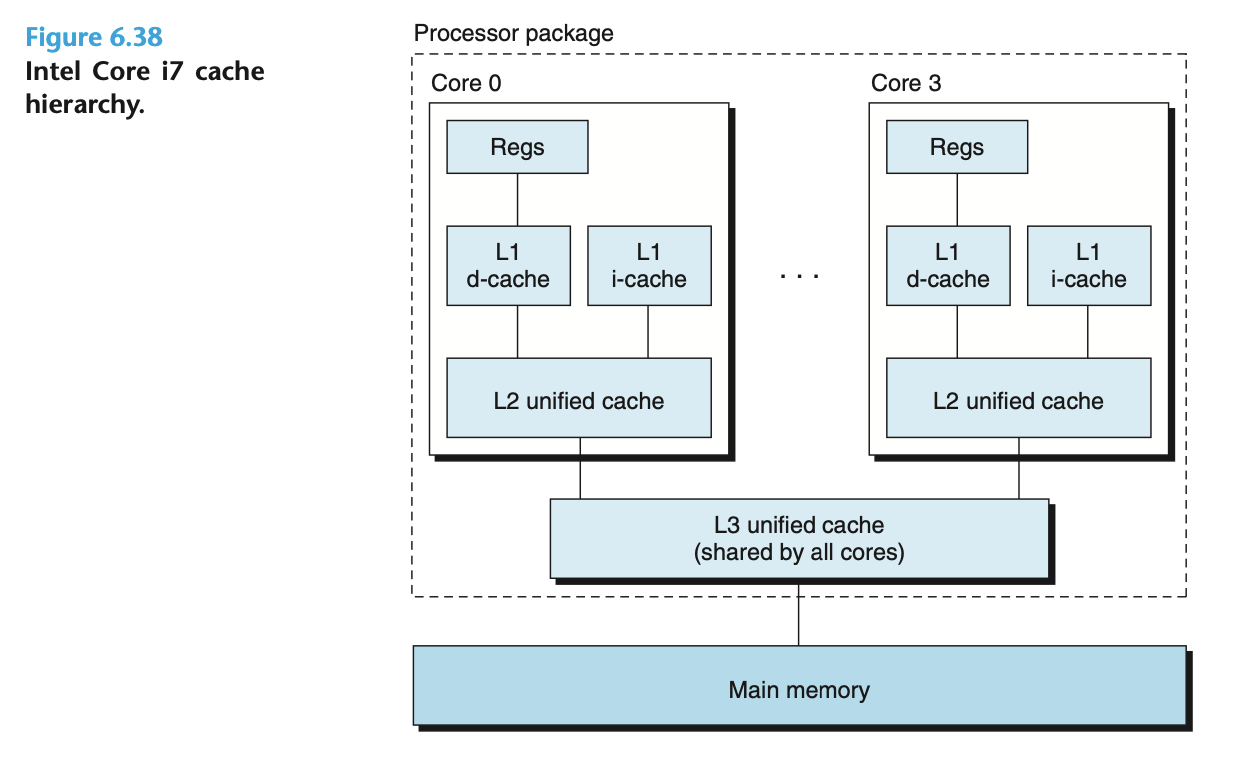
只存储"数据"的缓存称为 d-cache, 只存储"指令"的缓存称为 i-cache, 不作此区分的缓存称为 unified cache.
Intel Core i7 的内存缓存结构: