[技术向] 存储系统 (MySQL)
MySQL 属于传统的关系型 (结构化) 数据库, OLTP.
关系数据库三范式
[ 1NF ] 列不可再分 (原子性)
[ 2NF ] 属性依赖于主键
[ 3NF ] 属性直接依赖于主键 (例子: 学生为主键 - 学院为属性)
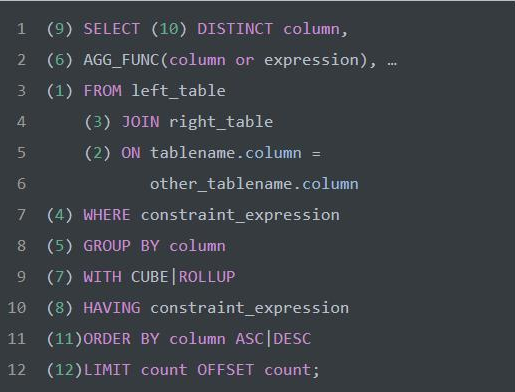
一个 SQL 语句的执行顺序
索引
索引的本质是通过空间换时间, 利用额外的存储来加速查询. 主键本身是唯一索引.
索引失效条件:
在索引列上做任何操作 (计算, 函数, 隐式类型转换)
索引范围条件右边的列
不等于/判空
LIKE以通配符 (%) 开头
联合索引
假设建立了联合索引 KEY(a, b, c), 那么在 MySQL 中, WHERE 语句会对过滤顺序进行优化:
-- 下面两条语句的效果是一样的
SELECT * FROM tbl_xxx WHERE a = ? AND b = ? AND c = ?
SELECT * FROM tbl_xxx WHERE a = ? AND c = ? AND b = ?
-- 注意范围查询也属于 "断点"
-- 下面两条语句都只用到 a
SELECT * FROM tbl_xxx WHERE a = ? AND c = ?
SELECT * FROM tbl_xxx WHERE a = ? AND b > ? AND c = ?存储引擎
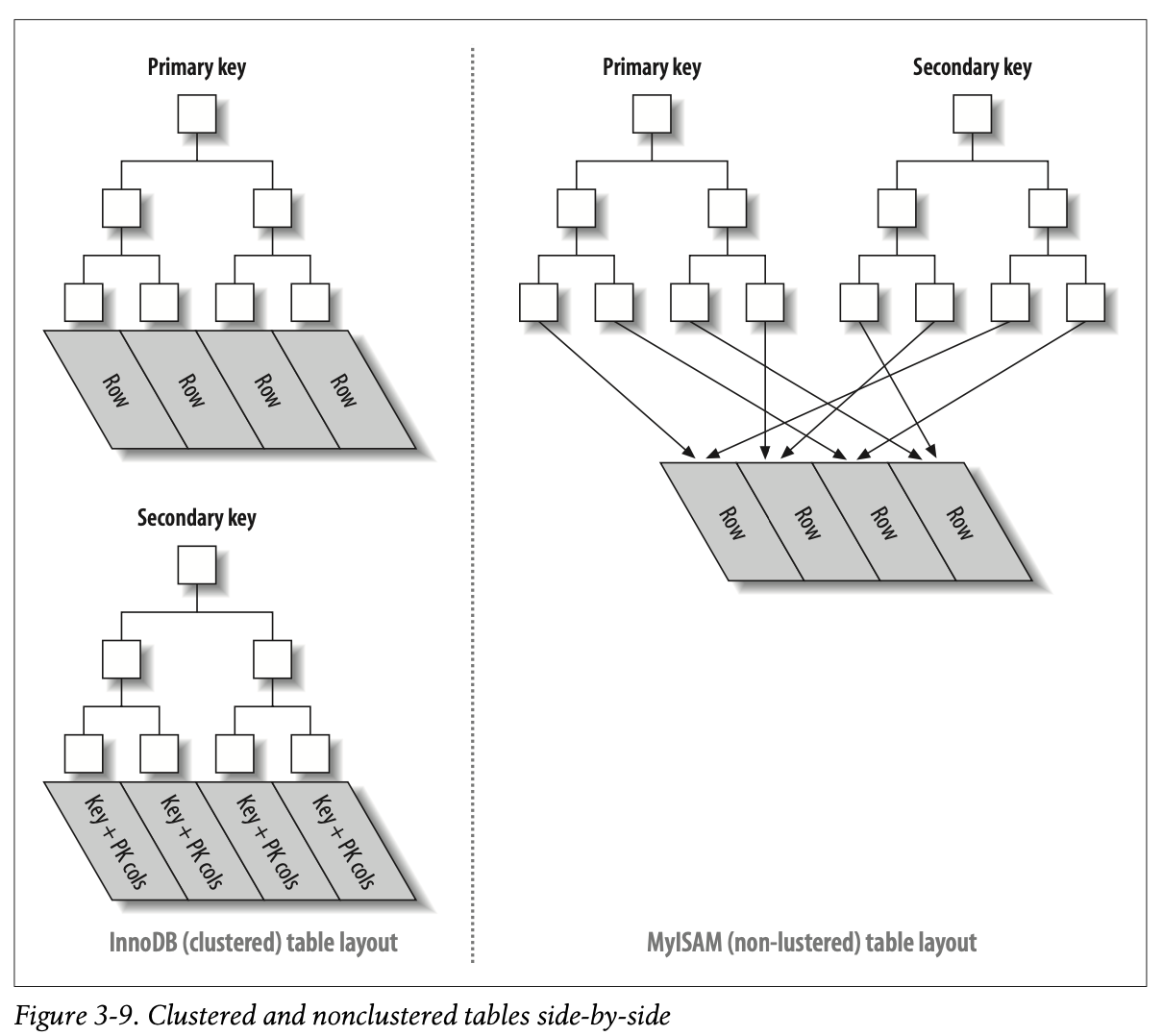
InnoDB 使用聚簇索引, 数据按主键顺序排列 (行数据跟主键存放在一起), 支持事务/外键/行级锁.
MySAMI 使用非聚簇索引, 数据按插入顺序排列 (行数据和主键在物理上分离), 不支持事务/外键/行级锁, 只支持表锁, 支持全文索引.
由于 MySAMI 不支持事务, 大部分情况下使用 InnoDB. 前者的优势在于查询效率更高.
事务
四种隔离级别: 读未提交, 读提交, 可重复读 (默认), 序列化.
-- 查看隔离级别
SHOW VARIABLES LIKE '%tx_isolation%';
-- 设置隔离级别
SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL
{READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE};在默认的隔离级别下, 会产生幻读 (phantom read), 事务 A 的写操作会影响事务 B 的查询结果.
基于多版本并发控制 (MVCC) 的快照隔离机制能保证事务 B 在只读的情况下, 读到一致的结果, 也就是"可重复读". 但对于事务 B 会根据读的结果再进行写 (read-write) 的情形, 则可能会违反应用层面的一些约束.
例子: 对于一个医院管理系统, 应用层面要求每个时刻必须有至少一个医生值班. 一开始 Alice 和 Bob 都处于值班状态, 两人同时发起 count 查询当前值班人数 (=2), 发现满足约束, 并将自己置为下班状态. —— 虽然两个事务在数据库层面没有发生冲突, 但在应用层面上存在竞态条件.

幻读的解法
方式一: 手动对查询涉及到的行加上互斥 (X) 锁, 语法上通过 FOR UPDATE 来实现, 从而使不同事务序列化执行.
BEGIN TRANSACTION;
SELECT * FROM doctors
WHERE on_call = true
AND shift_id = 123 FOR UPDATE;
UPDATE doctors
SET on_call = false
WHERE name = 'Alice'
AND shift_id = 1234;
COMMIT;方式二: 使用数据库本身的序列化机制. 以InnoDB 为例, 设置了 SERIALIZABLE 隔离级别后, 读操作就会自动加锁. 又分两种情况:
没有使用索引, 加表锁.
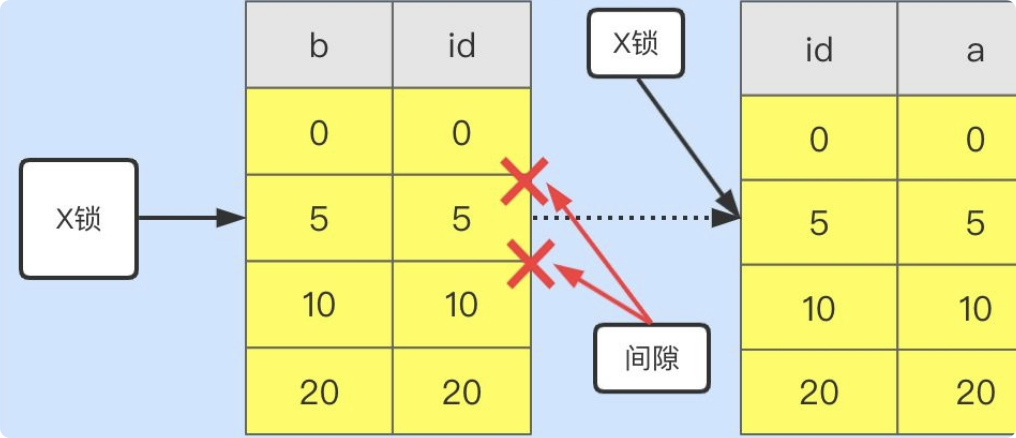
使用索引, 加 next-key Lock (间隙锁和行锁的组合). 如果索引具有唯一性, 就只加行锁.
间隙锁 (Gap Lock) 是在索引不唯一的情况下对左右区间加锁, 保证不会新增具有相同索引值的数据.
日志
[ redo log ] 是物理日志, 用于保证事务持久性 (D):
记录数据页的物理修改, 而不是关系型模型中的某行修改成什么样子
用来恢复提交后的物理数据页, 保证 crash-safe.
采取循环写, 会边写边擦除日志, 只记录未被刷入磁盘的数据.
如果需要备份恢复, 只能依靠二进制日志 (binlog).
[ undo log ] 逻辑日志, 用于保证事务原子性 (A):
回滚行记录到某个版本.
主从备份
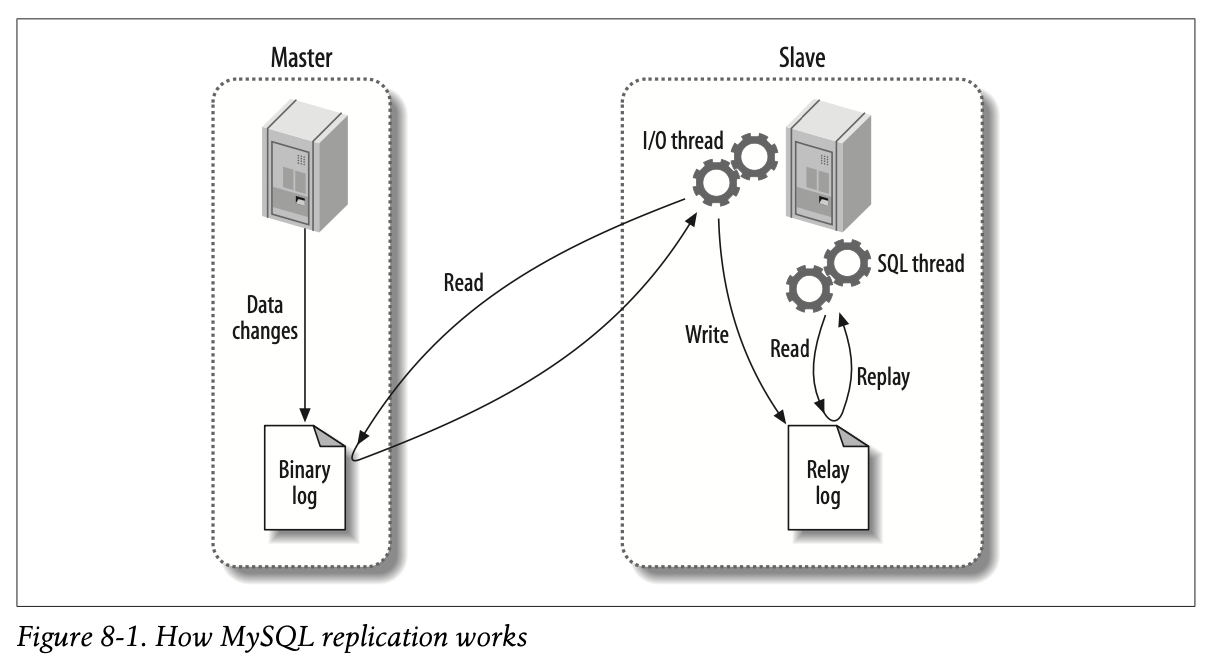
从库从主库拉取 binlog, 转换成 SQL, 按照标准流程去执行, 这种思路跟 Paxos/Raft 基于日志序列的备份是一致的.
个人理解: relay log 相当于从 binary 转成 SQL 执行过程中的 buffer.
如果主从延迟较为严重, 有以下解决方案:
手动分库, 将一个主库均匀拆分为 N 个主库, 每个主库的写并发就变成原来的 1/N
打开 MySQL 支持的并行复制, 多个库并行复制 (如果某个库的写入并发特别高, 那么并行复制还是没意义)
设置直连主库 (下策)