[技术向] 存储系统 (Redis)
Redis 是一种键值型 (key-value) 内存数据库, 广泛用于缓存.
数据结构
string / list / hash / set / zset
zset 跳表
多级索引:
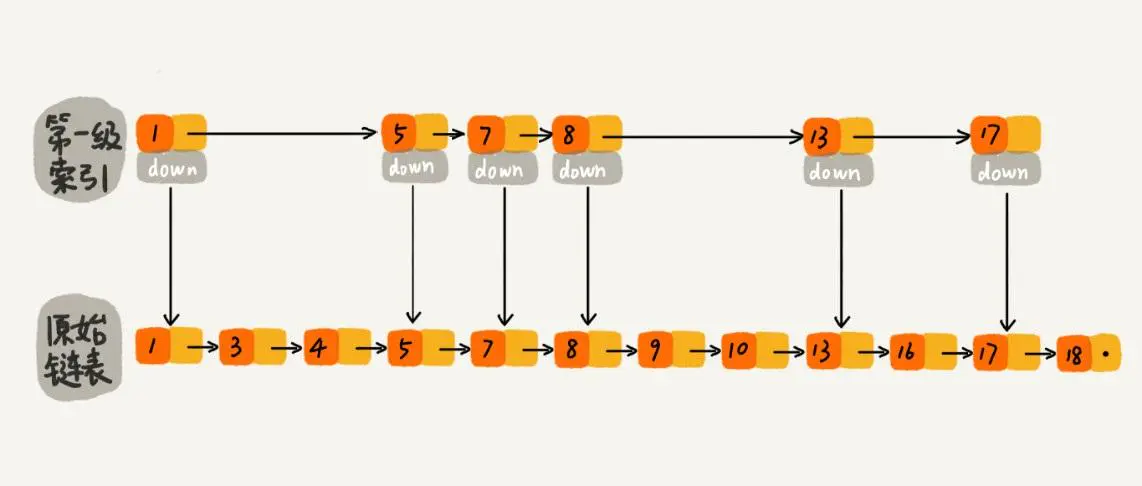
令 P 表示索引的密集程度, 假设为 .5, 那么新增一条记录时, 令:
建立一级索引的概率为 P (=.5)
建立二级索引的概率为 P^2 (=.25)
以此类推, 这是一种简洁高效的跳表维护方法. 个人理解, 跳表是对链表和有序数组的折中, 达到 O(logN) 的读/写操作.
渐进式哈希
Redis 在对哈希表进行扩容后, 不会同步迁移所有数据, 而是继续处理客户端的请求. 每次处理一个请求, 就会将字典结构中的 rehashIdx 字段 (初始化为 0) 位置的所有键值对拷贝到新的哈希表中, 然后将 rehashIdx 递增.
字典可能在一段时间内不会被访问, 所以 Redis 还会设置一个定时任务, 周期性地迁移一些数据.
过期策略
key 可以设置有效期 (TTL), Redis 的内部实现是"惰性删除"和"定期删除"相结合.
[ 惰性删除 ] 访问一个 key 时检查是否过期, 如果是就删除, 这种方案不需要额外的定时器, 对 CPU 比较友好. 缺点是, 过期的 key 不被访问就会一直占用内存. 显然, 惰性删除和常见的懒加载策略有异曲同工之妙, 不同之处在于, 在删除的场景中, 如果长期不触发操作则不利于系统运行, 所以要引入额外的策略.
[ 定期删除 ] 为了弥补惰性删除可能导致内存占用过高的缺陷, Redis 会每隔一段时间扫描数据库 (默认间隔 100 ms). 不会扫描所有的 key, 而是随机检查 20 个带有过期时间的 key. 如果超过一定比例的 key 过期, 那么会重复这个步骤. 会限制扫描时间, 以免占用太多 CPU 资源.
持久化
[ RDB ] 快照, 记录当前所有 key 的状态.
[ AOF ] 增量日志, 记录操作序列.
缓存失效 (应用场景)
所谓缓存失效, 包括三种情况:
[ 缓存雪崩 ] 主要出现在缓存服务宕掉后, 所有的流量会打到数据库上, 导致数据库也挂掉. 对策是, 建立 redis 集群 (主从 + 哨兵), 保证高可用, 避免全盘崩溃. 辅助的方法还有限流降级, 避免数据库短时间内收到大量请求, 以及开启 redis 持久化, 重启后快速恢复.
[ 缓存穿透 ] 是一种恶意攻击的手段, 它会构造大量的请求去查询一些缓存中肯定没有的数据 (比如 id 为 -1), 迫使所有的请求都打到数据库上面, 从而导致数据库宕机. 解决方案是对所有查不到的值, 在缓存中创建一个空值. 显然, 这种对策并不周全, 攻击者的每个请求都可以构造一个新值, 更好的办法是运用布隆过滤器对请求进行拦截.
[ 缓存击穿 ] 即 single flight, 在一个 hot key 失效的瞬间, 大量对它的请求会击穿缓存, 打到数据库上面. 对策是, 将 hot key 设置为永不过期, 或者对请求进行限流.
主从备份
主从关系通过 replicaof 命令建立.
总体来说, 这是一种快照 + 增量备份的机制. 主节点生成 RDB 后发送给从节点. 从节点清空本地数据, 从 RDB 重新加载. 这个过程中, 主节点依然可以接收写命令, 变动的部分会记录在 replicaiton buffer 里. 最后主节点再不断将缓冲区的数据发送给从节点.
哨兵监控
哨兵会周期性地给所有的主从库发送 PING 命令, 如果从库没有响应 PING 命令, 哨兵就会将它标记为 offline; 如果主库没有响应, 哨兵也会标记 offline, 开始切换主库 (选主).
选主过程是, 先按照 slave 优先级进行排序. 如果优先级相同, 就比较 replication offset, 也就是看哪个 slave 复制了最多的数据. 如果前面两个条件都相同, 就比较 run id (每次启动的时候随机生成的), 选择 run id 较小的作为新的 master.
在网络出现隔离的情况下, 如何避免脑裂:
配置 min-slave-to-write , 表示写数据成功最少同步的 slave 数量, 从而实现类似 raft 的 majority 机制.