[技术向] Kubernetes 的核心组件与对象
Kubernetes 的目的是实现分布式大规模集群的自动化运维, 底层依赖于容器技术, 优势在于, (1) 根据面向对象的设计思想对常见的运维操作进行了高度抽象, (2) 使用声明式 API 简化操作.
总体架构:
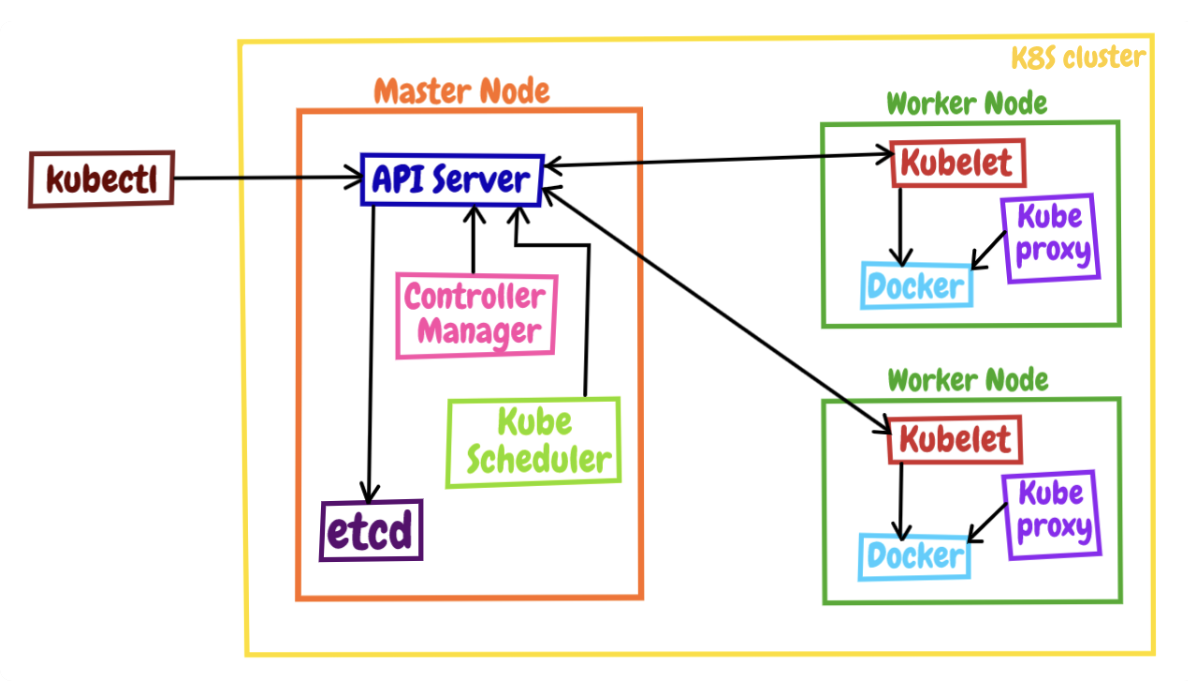
(图片来源: https://medium.com/@keshiha/k8s-architecture-bb6964767c12)
K8s 采用"控制面 / 数据面" (Control Plane / Data Plane) 架构, 集群里的计算机称为节点, 可以是实机也可以是虚机, 少量的节点 (Master) 用作控制面来执行集群的管理维护工作, 其他的大部分节点 (Worker, 下文直接记为 Node) 都被划归数据面, 用于运行业务应用.
kubectl 是 K8s 的客户端工具, 用来发送集群操作请求, 它位于集群之外, 理论上不属于集群.
K8s 的节点内部是由多个模块构成的, 可以分成组件 & 插件.
Master 有 4 个组件:
[ apiserver ] 是整个 K8s 系统的唯一入口, 对外公开了一系列的 RESTful API, 并且加上了验证、授权等功能, 所有其他组件都只能和它直接通信.
[ etcd ] 是一个高可用的分布式 Key-Value 数据库, 用来持久化存储系统里的各种资源对象和状态; 它只与 apiserver 有直接联系, 其他组件想要读写 etcd 的数据都必须经过 apiserver.
[ scheduler ] 负责容器的编排工作, 检查节点的资源状态, 把 Pod 调度到最适合的节点上运行, 这些节点的状态和 Pod 信息都存储在 etcd 里.
[ controller-manager ] 负责维护容器和节点等资源的状态, 实现故障检测、服务迁移、应用伸缩等功能, 更多倾向于运维监控.
这 4 个组件也都被容器化了, 运行在集群的 kube-system 命名空间里.
Node 有 3 个组件:
[ kubelet ] 是 Node 的代理, 负责管理 Node 相关的绝大部分操作, Node 上只有它能够与 apiserver 通信, 实现状态报告、命令下发、启停容器等功能.
[ kube-proxy ] 是 Node 的网络代理, 只负责管理容器的网络通信, 为 Pod 转发 TCP/UDP 数据包.
[ container-runtime ] 是容器和镜像的实际使用者, 在 kubelet 的指挥下创建容器, 管理 Pod 的生命周期.
这 3 个组件中只有 kube-proxy 被容器化了; kubelet 要管理整个节点, 容器化会限制它的能力, 所以它必须在 container-runtime 之外运行.
对象关系
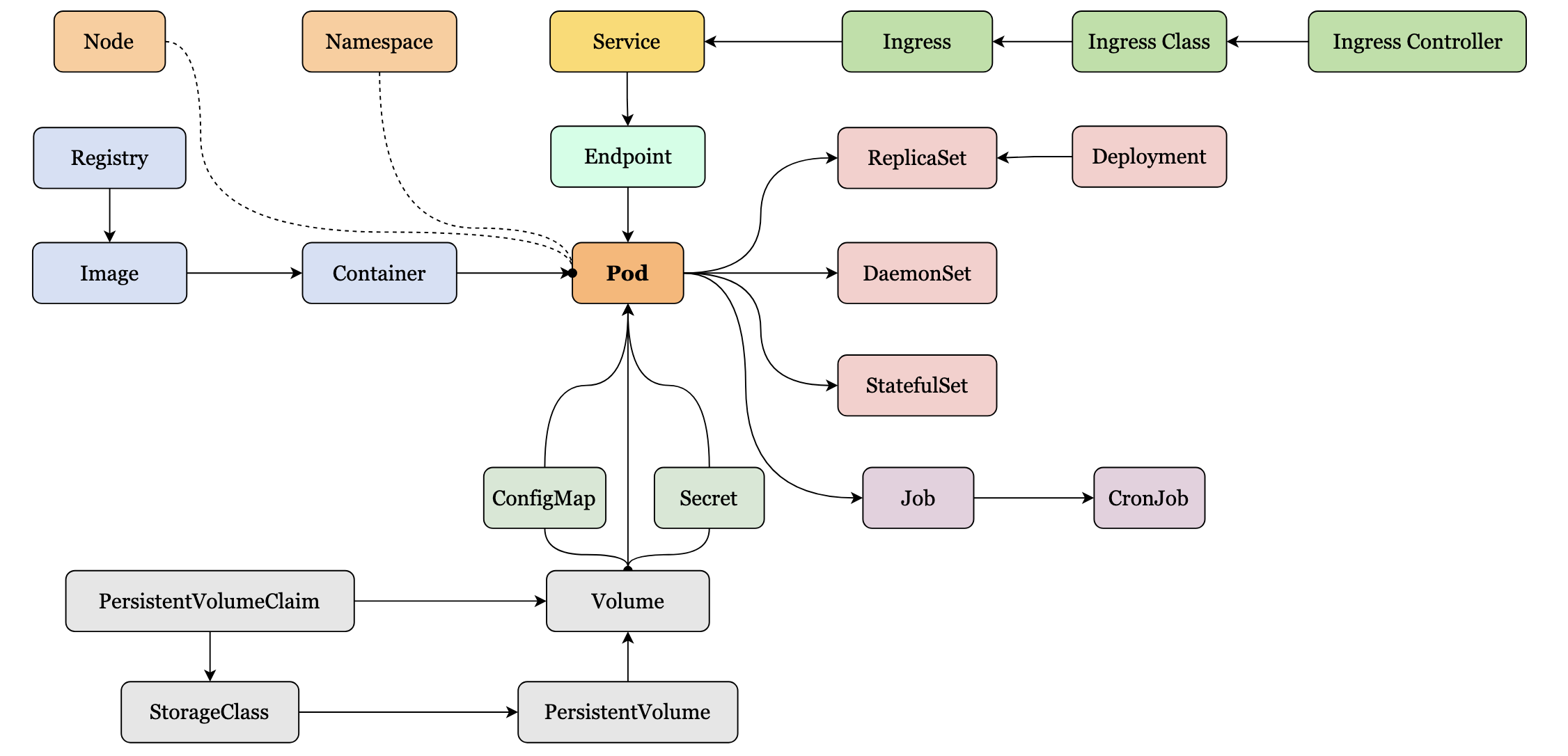
Pod 是对容器的"打包", 里面的容器是一个整体, 对容器的操作都在 Pod 中进行. 可见, Pod 的作用是让多个容器既保持相对独立, 又能够小范围共享网络 & 存储等资源, 而且总是一起调度, 一起运行.
K8s 让 Pod 去编排处理容器, 然后把 Pod 作为应用调度部署的最小单位. 所有的 K8s 资源都直接或者间接地依附在 Pod 之上.
K8s 中的对象关系遵循 "组合优于继承" 的思想.
Node 的 yaml 配置示例:
apiVersion: v1
kind: Pod
metadata:
name: busy-pod
labels: # 标签, 方便 K8s 对不同应用的识别和管理
owner: me
env: demo
region: north
tier: back
spec:
containers:
- image: busybox:latest
name: busy
imagePullPolicy: IfNotPresent # 若本地没有镜像文件, 从远程拉取
restartPolicy: Always # 发生异常会自动重启容器
env: # 环境变量
- name: os
value: "ubuntu"
- name: debug
value: "on"
command: # 运行命令
- /bin/echo
args: # 运行参数
- "$(os), $(debug)"Job & CronJob
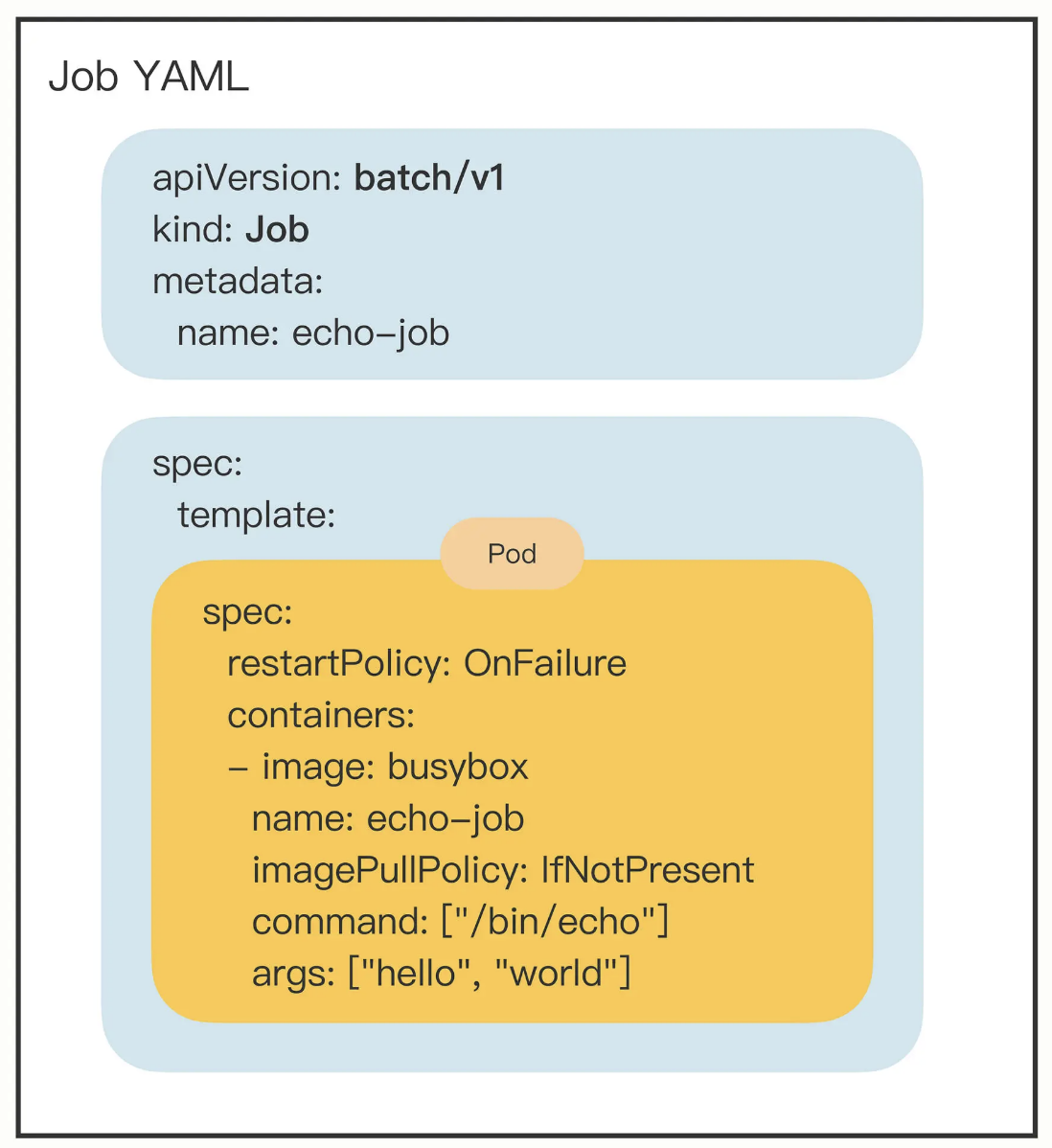
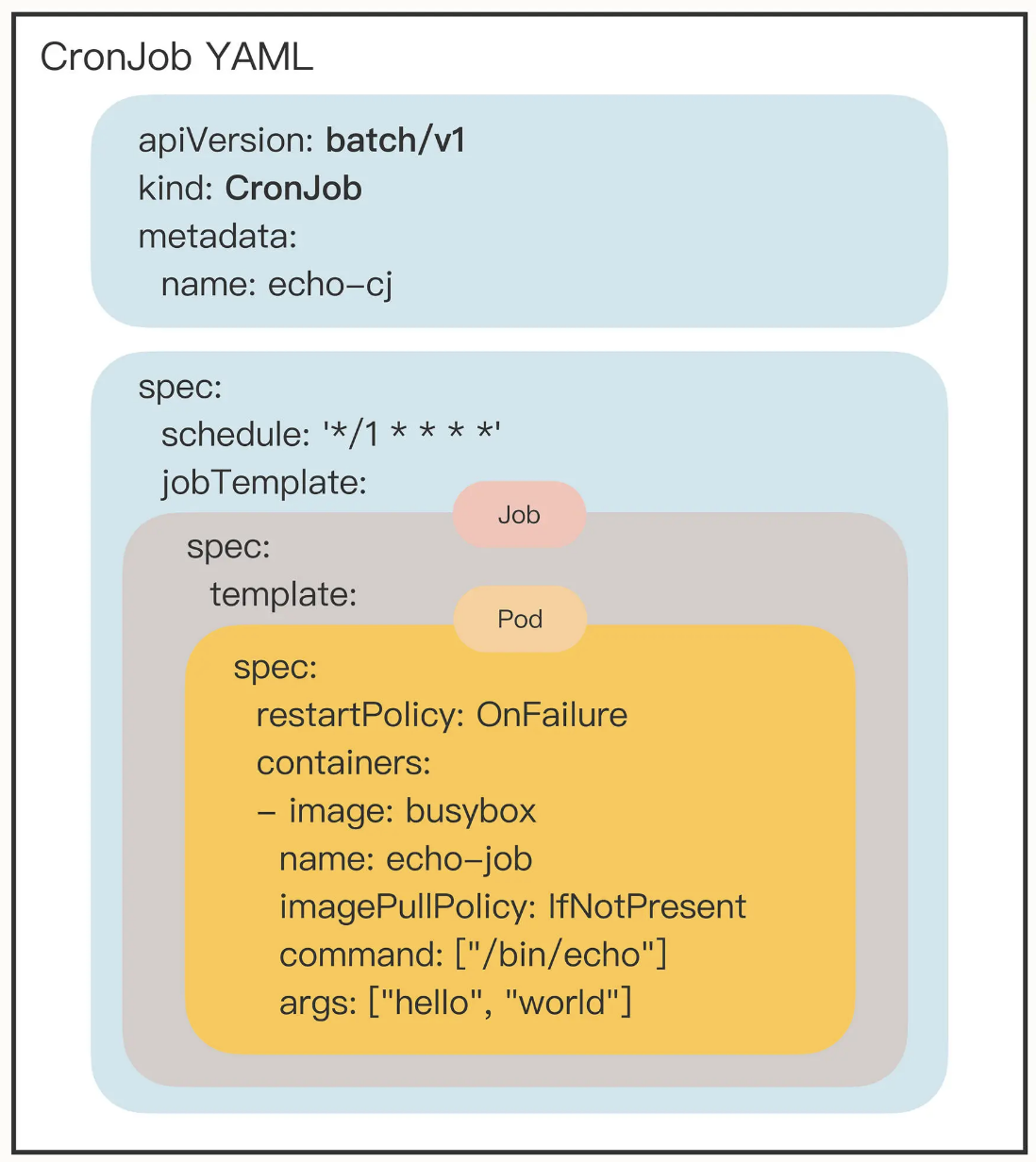
批处理(离线调度)的任务抽象:
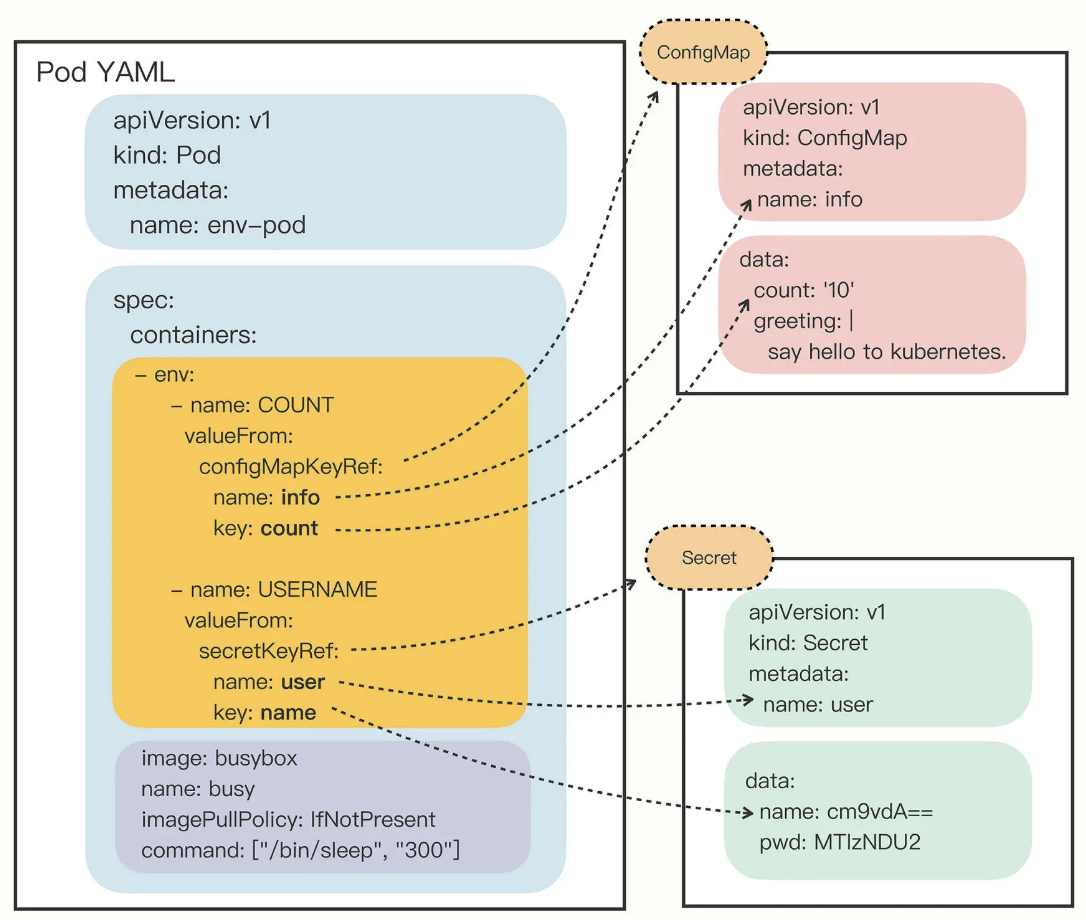
ConfigMap & Secret
配置信息, 有明文和密文的区别:
Deployment
负责在线应用 (也就是真正意义上的"服务") 的部署:
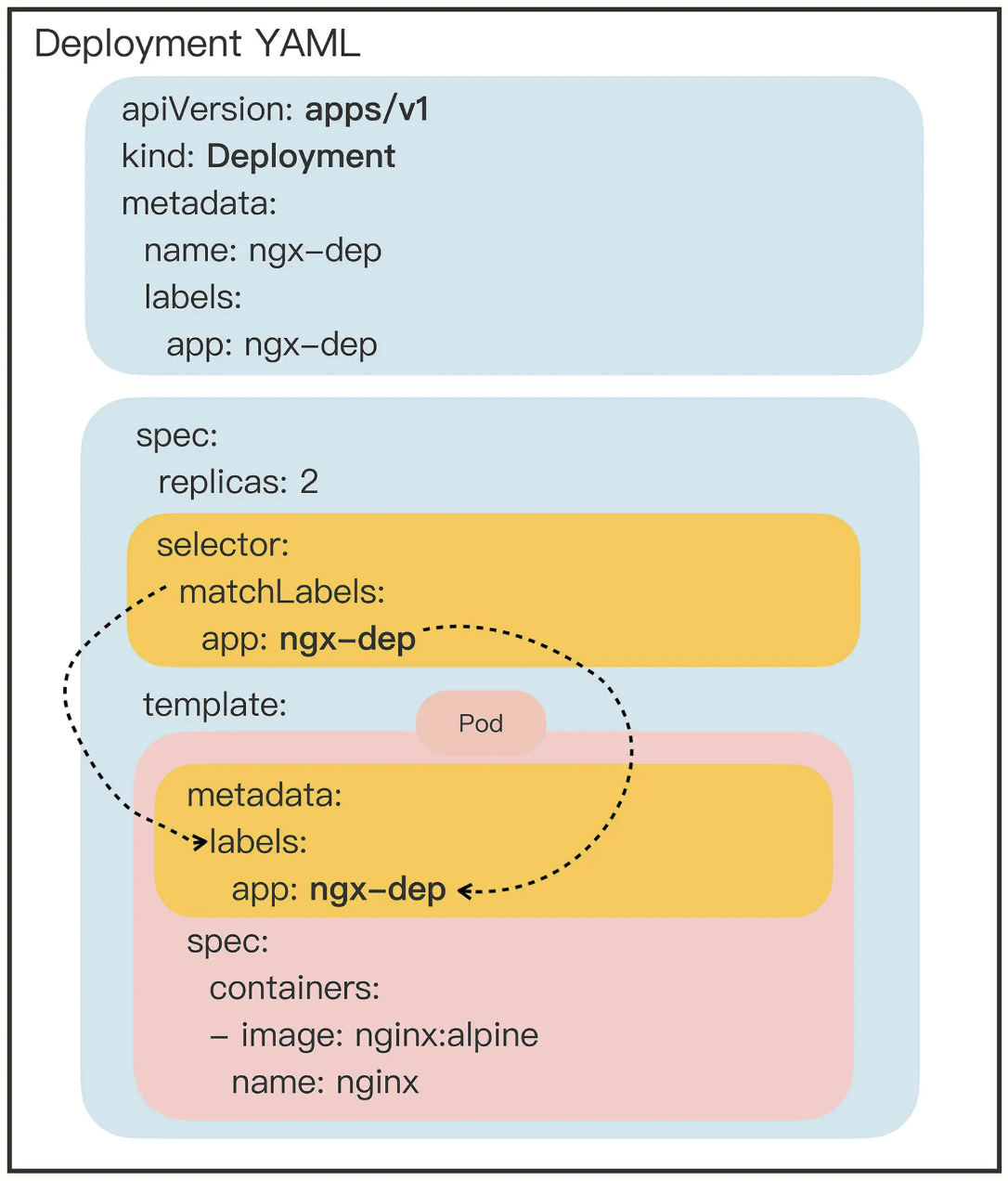
Deployment 可以创建任意多个的 Pod 实例, 并且维护这些 Pod 的正常运行, 保证应用始终处于可用状态.
Deployment 和 Pod 是一种松散的组合关系, Deployment 实际上并不"持有" Pod 对象, 这种组合关系通过标签来实现.
DaemonSet
在集群的每个节点上运行且仅运行一个 Pod:
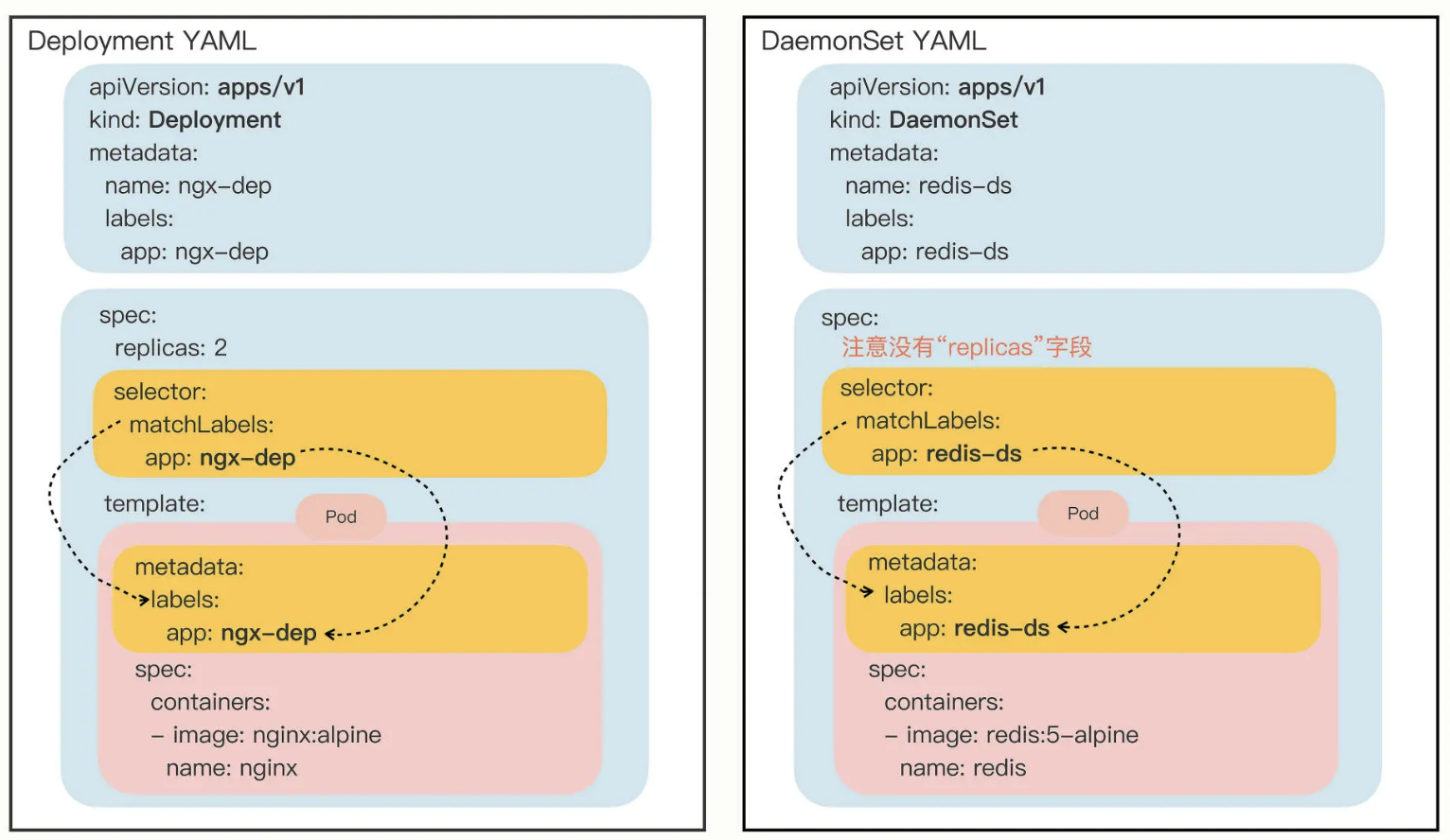
DaemonSet 是为了弥补 Deployment 的不足, 后者不关心 Pod 会在集群的哪些节点上运行, 在它看来, Pod 的运行环境与功能是无关的. 但是, 有一些业务不是完全独立于系统运行的, 而是与主机存在"绑定"关系, 必须要依附于节点才能产生价值, 比如:
网络应用 (kube-proxy), 监控应用 (Prometheus), 日志应用 (Fluentd), 安全应用等等.
Service
TCP/IP 协议层面的服务发现和负载均衡:
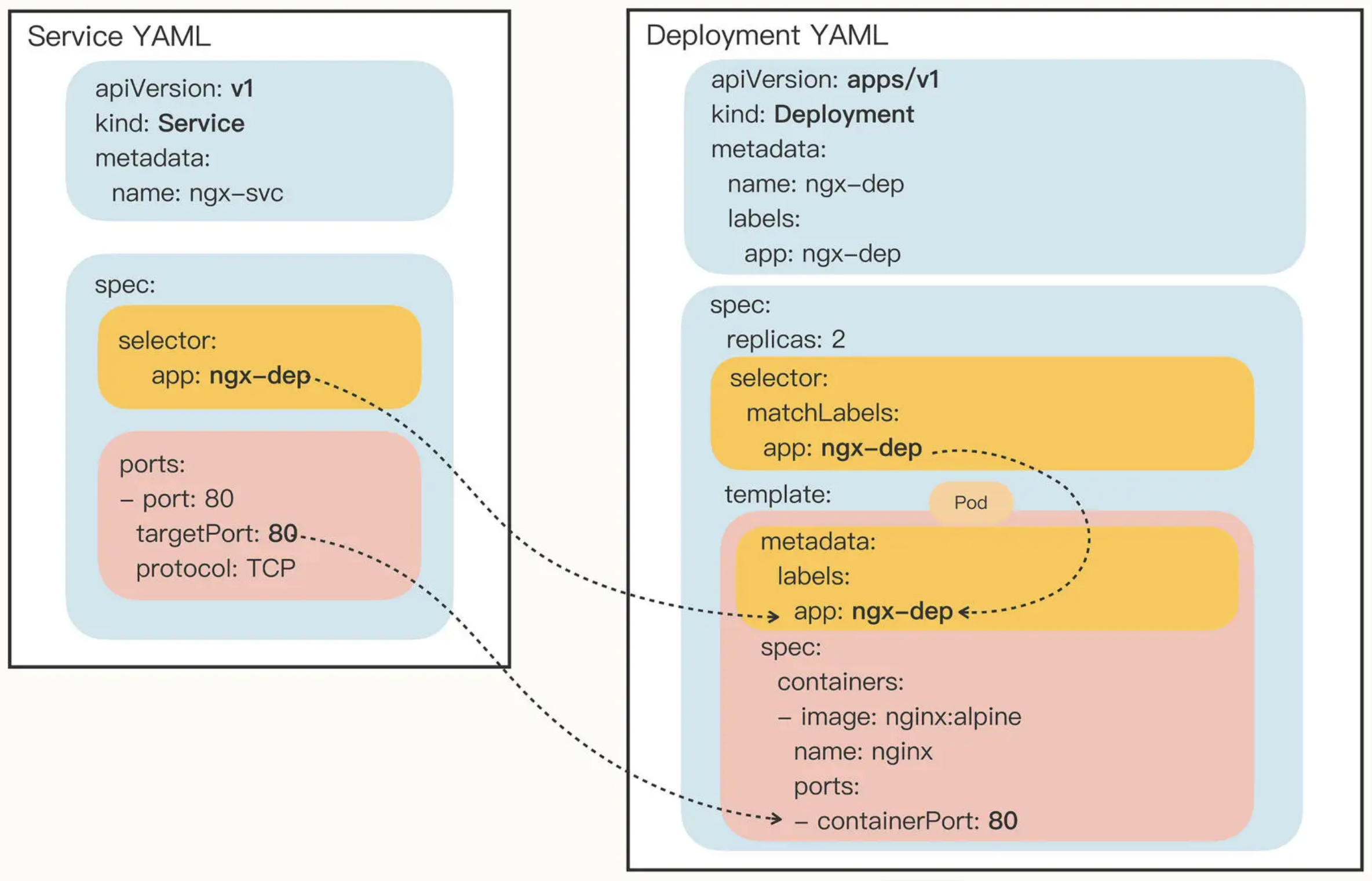
Service 本质上是一个由 kube-proxy 控制的四层负载均衡, 在 TCP/IP 协议栈上转发流量, 使用静态 IP 地址代理动态的 Pod, 后者在集群内部的 IP 往往会随着升级/重启而变化.
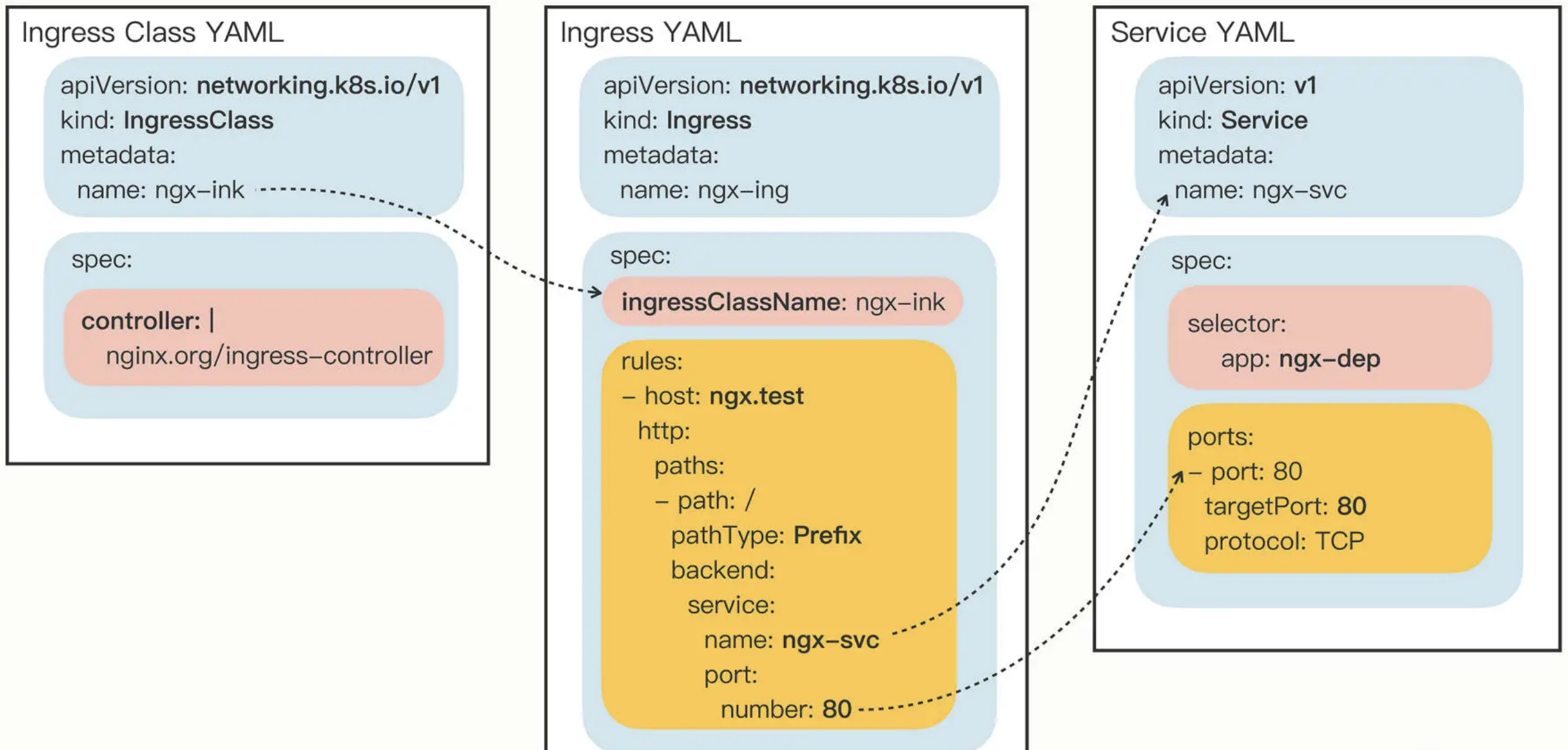
Ingress
HTTP 流量入口的管理:
PersistentVolume
数据持久化 (存储) 的抽象:
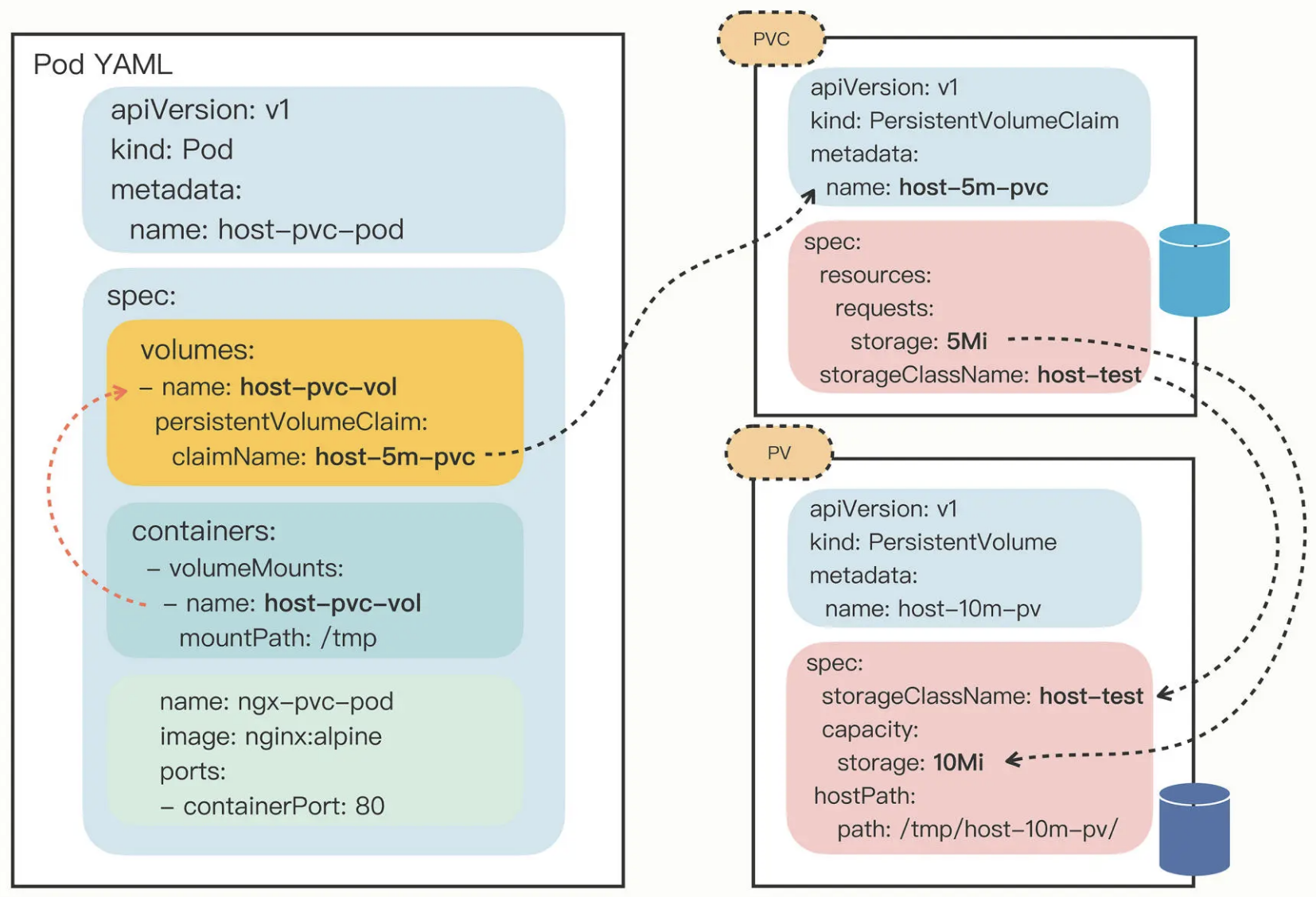
PV 代表了一些实际的存储设备、文件系统, 比如 Ceph、GlusterFS、NFS, 甚至是本地磁盘.
存储设备一般由系统管理员单独维护, 然后再在 Kubernetes 里创建对应的 PV, 它们属于集群的系统资源, 是和 Node 平级的一种对象, Pod 对它没有管理权, 只有使用权.
PersistentVolumeClaim (PVC), StorageClass 两个对象是把存储卷的分配管理过程再次细化, 体现了中间层的思想:
PVC 相当于是 Pod 的代理, 代表 Pod 向系统申请 PV, 一旦资源申请成功, K8s 就会把 PV 和 PVC 绑定在一起.
StorageClass 抽象了特定类型的存储系统 (比如 Ceph、NFS), 帮助 PVC 找到合适的 PV, 它简化了 Pod 挂载"虚拟盘"的过程, 让 Pod 看不到 PV 的实现细节.
示例:
-- PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: host-10m-pv
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce # 可读可写, 但只能被一个节点上的 Pod 挂载
capacity:
storage: 10Mi # 存储设备的容量
hostPath:
path: /tmp/host-10m-pv/ # 指定了存储卷的本地路径
-- PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: host-5m-pvc
spec:
storageClassName: host-test
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Mi -- 期望申请的容量