[技术向] Spark 架构与运行过程
数据抽象
Spark 的模型基石是 RDD, 一种分布式计算的数据抽象, 特性如下:
不可变 : RDD 的内容和分区结构在创建后不可修改, 只能通过转换 (map / filter) 生成新的 RDD, 避免多节点并发修改的冲突
可分区 : 每个分区是最小计算单元, 分布在不同节点, 默认为 HDFS 文件块数 / 集群的 Executor 总核心数
容错性 : 当某个分区数据丢失时, 可通过依赖关系重新计算恢复, 无需依赖外部存储的备份
RDD 在源码中的解释:
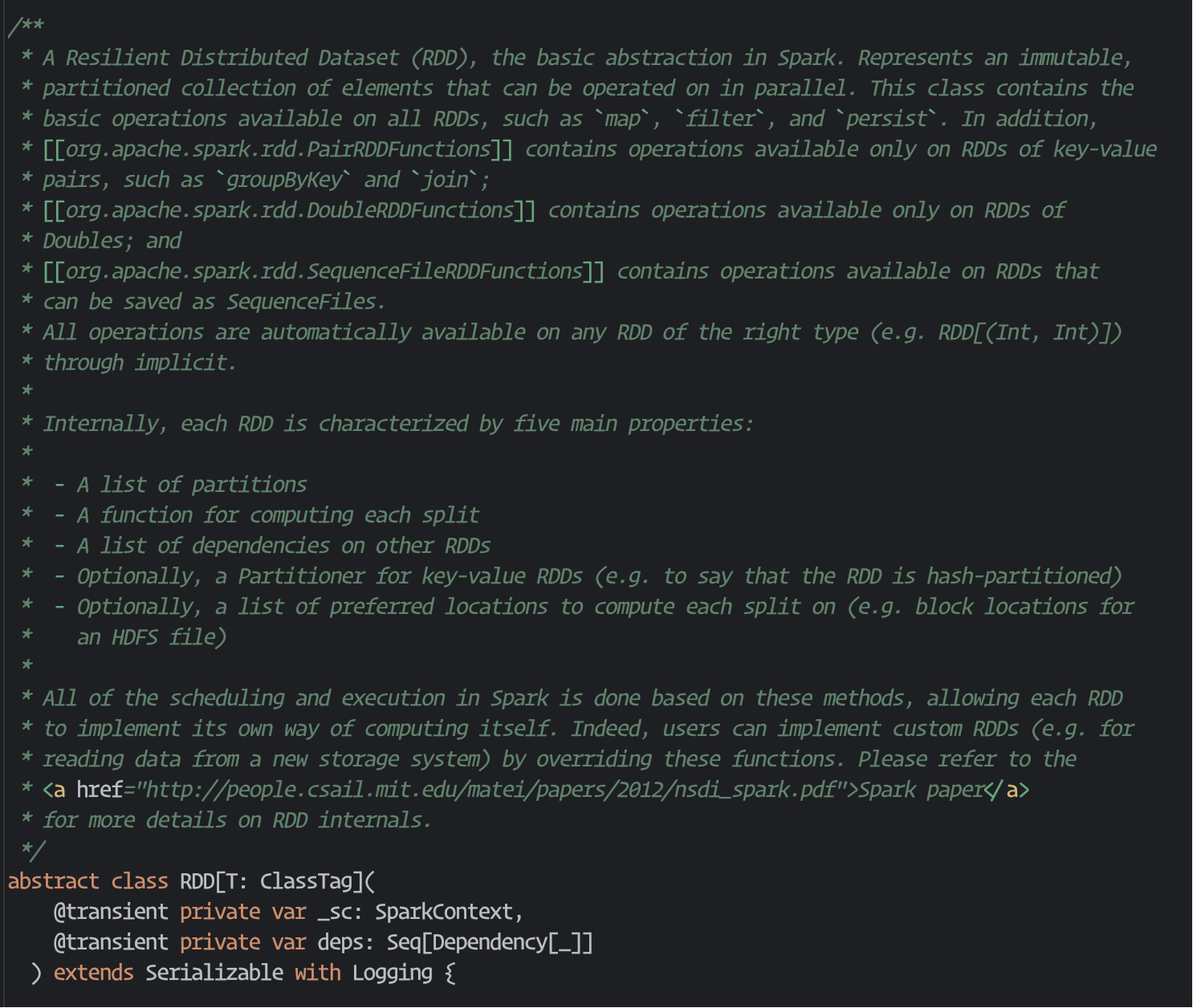
可以看到, RDD 内部定义的元数据是:
分区列表 : 记录每个分区的数据索引
依赖关系 : 描述当前 RDD 与父 RDD 的依赖关系
计算函数 : 如何根据父 RDD 的分区计算当前 RDD 的分区
分区器 : 仅对 kv 类型的 RDD 有效, 决定如何分区 (如哈希分区、范围分区), 用于优化 shuffle 效率
首选位置 : 记录每个分区的最优计算节点 (如数据所在的 HDFS 节点), 实现"数据本地性"计算, 减少网络传输
算子
Spark 算子分为 转换算子 (Transformation) 和 行动算子 (Action) :
[ T ] 代表 RDD 之间的依赖 (血缘关系), 不会立即执行计算, 比如 map / filter, 是一种懒执行机制
[ A ] 触发计算, 根据血缘关系, 反向推导并执行所有转换, 比如 count / saveAsTextFile
依赖关系 —— Stage
在 Spark 中, RDD 之间的关系有"窄依赖"和"宽依赖"之分, 直接影响任务划分、数据 shuffle 以及容错机制.
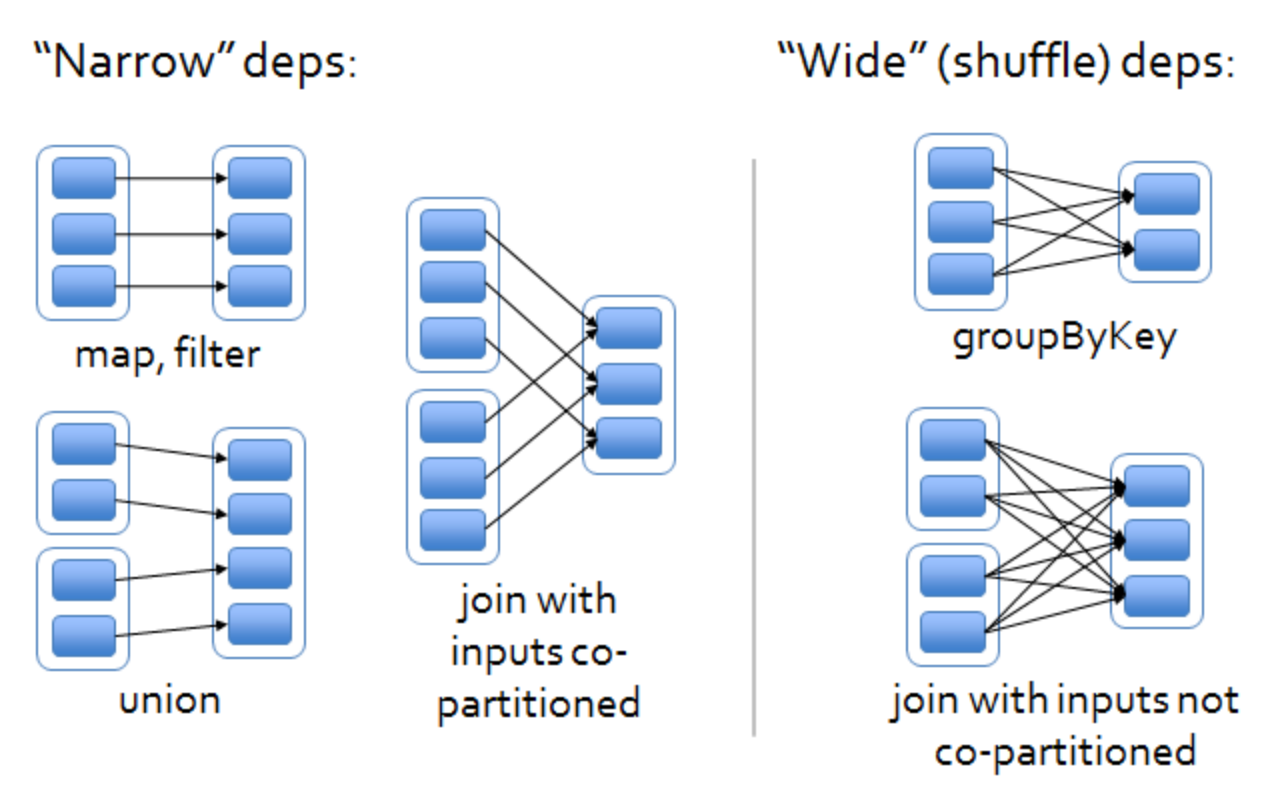
[ 窄依赖 ] 父 RDD 的每个分区只被子 RDD 的一个分区依赖, 反过来, 子 RDD 的一个分区的数据只来自父 RDD 的少数几个 (通常是 1 个) 分区, 且不会跨节点传输大量数据, 常见操作有 map、filter、union、mapPartitions、flatMap, 特点 :
无 shuffle, 数据处理不需要跨节点传输
并行效率高, 每个分区的计算可独立进行
容错简单, 若子 RDD 分区丢失, 只需重算对应的父 RDD 分区
[ 宽依赖 ] 父 RDD 的一个分区被多个子 RDD 分区依赖, 子 RDD 的分区数据需要从父 RDD 的多个分区中获取, 常见操作有 groupByKey、reduceByKey、sortByKey、join (非广播) 等, 需要按 key 重新分区, 特点 :
有 shuffle, 数据需要根据 key 重新分区, 涉及磁盘 IO、跨节点传输
若子 RDD 分区丢失, 需要重算父 RDD 的多个分区
DAG 调度器会根据依赖关系划分 Stage, 以宽依赖作为 Stage 的边界. 同一个 Stage 内的操作均为窄依赖, 可并行执行.
需要注意, union 算子是窄依赖, 因为它只是将两个 RDD 的分区 "拼接" 起来, 不需要对数据进行重新分区或跨节点传输.
集群模式
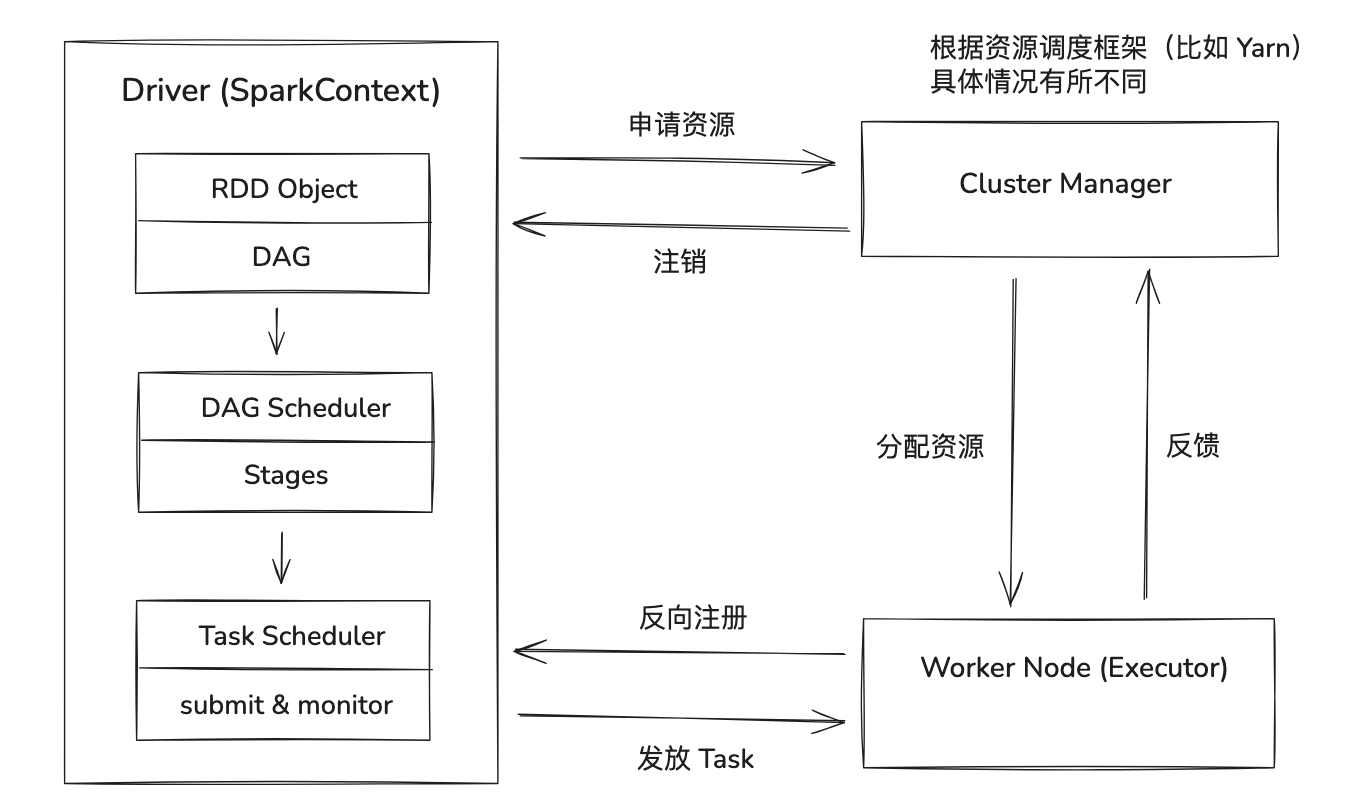
执行流程 :
构建 RDD 依赖关系
行动算子触发 DAG 解析
DAG 调度器根据 RDD 依赖关系划分 Stage, 以宽依赖为边界
每个 Stage 分成 n 个 Task (n = RDD 分区数量)
资源管理器分配节点作为 Executor, 主动向 Driver 注册
Driver 生成 Task 并分发到 Executor, 调度器会优先将 Task 分配到数据所在节点
Executor 从数据源 / 上游的 shuffle 结果读取数据, 根据 RDD 定义的 compute 方法执行计算
最终结果返回 Driver
参数
spark.default.parallelism: 默认并行度spark.sql.shuffle.partitions: SQL 作业中, shuffle 之后的分区数, 默认 200spark.sql.autoBroadcastJoinThreshold: 在 Join 的时候, 小于这个阈值的表会被广播, 默认 10MB