[技术向] CSAPP (深入理解计算机系统) 编译与链接
链接是指将多个代码/数据片段合并成单个可执行文件的过程, 可以发生在编译期/装载期/运行期, 大部分情况下由专门的链接器来完成. 链接器 (ld) 对于程序开发是必不可少的, 因为它允许分别编译 (separate compilation), 代码修改后只需要重新编译变更过的部分, 再重新链接, 无需编译其他不变的部分. 它也是共享库的基础.
编译驱动程序
大多数编译系统会提供编译驱动程序, 在用户需要时调用 <语言预处理器, 编译器, 汇编器, 链接器>.
编译驱动程序的工作流程,以 gcc 为例:
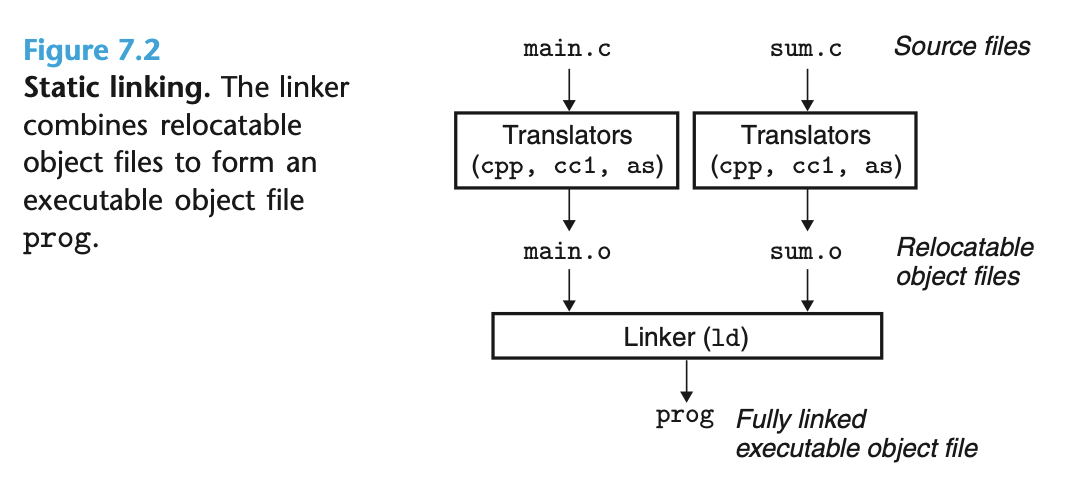
先运行 C 预处理器 (cpp), 将源码文件
main.c转译成中间文件main.i运行 C 编译器 (cc1), 将中间文件
main.i转译成汇编文件main.s运行汇编器, 将汇编文件
main.s转译成可重定位 (relocatable) 的目标文件main.o对于
sum.c, 也是同样的步骤最后, 链接
main.o和sum.o得到可执行的目标文件
通过 shell 运行 ./prog, 此时 shell 会调用操作系统的装载程序, 将可执行文件的代码和数据拷贝到内存中, 再把控制权转移到程序第一条指令的位置.
下面这张图更清晰:
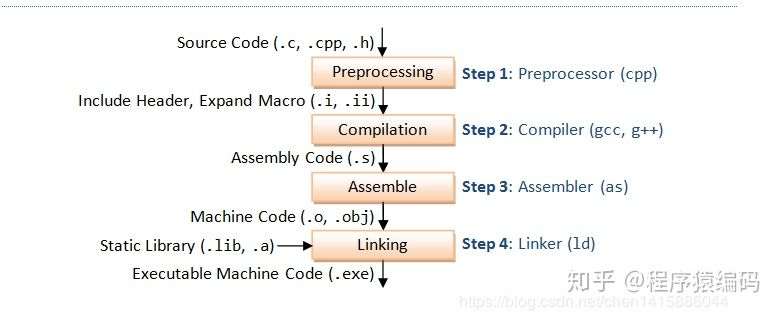
静态链接
Linux 中的 LD 程序就属于静态链接, 接收若干可重定位的目标文件和命令行参数, 生成一个完整链接 (fully-linked, 相对于 dynamic-linked) 的可执行文件.
链接器的主要工作包括:
[ 符号解析 ] 目标文件定义和引用了许多 symbol, 可以代表一个函数/全局变量/静态变量. 符号解析的目的是准确建立 symbol 的 “定义” 和 “引用” 之间的联系.
[ 重定位 ] 目标文件中的各个代码区和数据区均以 0 为起始地址. 链接器会给每个 symbol 分配一个虚拟内存地址, 在此基础上修改符号的引用, 实现重定位.
目标文件
目标文件仅仅是一些二进制块, 分成若干区域 (section), 有些包含程序代码, 有些包含程序数据, 还有一些包含指导链接器和加载器的数据结构. 链接器负责将这些二进制块连接在一起, 决定运行时的各种位置. 大部分与目标机器相关的工作是由编译器和汇编器完成的, 链接器对此了解甚少.
目标文件有 3 种形式:
[ 可重定位的 ] 包含二进制代码和数据, 仍未链接.
[ 可执行的 ] 链接好的, 能够被 load 进内存直接执行.
[ 共享的 ] 可以被动态链接和 load.
不同系统的目标文件格式各异, 现代的 Linux 系统使用 ELF 格式 (Executable & Linkable Format).
可重定位的目标文件
ELF 格式下, 可重定位的目标文件内部划分如下:

符号表
符号表是汇编器创建的, 保存在 .symtab 区域, 其初始依据是编译器输出的符号, 但并不是完全照搬.
目标文件中的符号表只包含函数和全局变量 (以及诸如 C 语言中的静态变量); 编译过程的符号表则还包括局部变量.
局部变量是在运行期间在栈上管理的, 不在链接器的职责范围内.
一个符号表的条目一般包含以下内容:

符号解析
链接器接收的输入是若干个可重定位的目标文件, 也就是说, 需要处理若干张符号表.
如前面说的, 所谓的符号解析就是准确建立符号定义和其引用之间的联系. 对于本地符号 (在模块内部定义, 并且没有被其他模块引用), 建立这一联系是比较简单的, 由编译器自己完成就可以了. 但是对于全局符号 (在一个模块内部定义, 被其他模块引用), 编译器会生成一个特殊条目, 让链接器去处理. 如果链接器在其他模块中没有找到这个符号的定义, 就会报错.
比如下面的 C 语言代码:
void foo(void);
int main() {
foo();
return 0;
}
// undefined reference to ‘foo’显然, 不同模块也有可能定义相同名字的全局符号. 为了应对这种情况, 编译器在将结果导出到汇编器的时候, 会给每个全局符号打上 strong/weak 的标志, 汇编器则会把这一信息编码到符号表中. 函数和已初始化的全局变量对应 strong 标志, 未初始化的全局变量对应 weak 标志. 接下来, 链接器会按照下列规则处理同名的全局符号:
不允许多个 strong 变量同名
对于一个 strong 变量和多个 weak 变量同名, 选择 strong 变量 (初始化的)
对于多个 weak 变量同名, 选择任意一个
对于规则 2 和 3, 如果变量的类型不一致 (比如 int 和 double), 链接器不一定会报错, 这样在运行时就会出问题, 也很难定位. 因此, 以 GCC 为例, 最好是加上 -fno-common 标志, 把同名全局符号一律当做错误处理.
链接的结果除了可执行的目标文件外, 也可以是静态库. 以静态库作为输入, 链接器只会链接被应用程序引用的那些模块. 在下图中, 对于静态库 libvector.a, 应用程序只引用了其中的 addvec 函数, 因此链接器只抽取了 addvec.o 和应用程序进行链接.
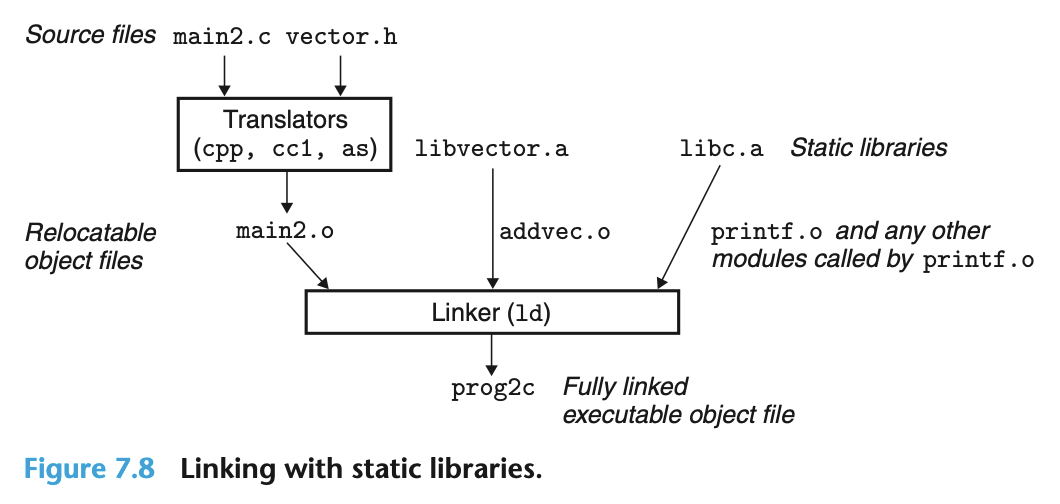
链接命令中的 -static 表示输出结果是完整的可执行目标文件:
gcc -c main2.c
gcc -static -o prog2c main2.o /libvector.a链接器对输入文件是按从左到右处理, 并且每个文件只处理一次. 如果把静态库放在最前面, 那么链接器会认为其中没有任何模块被引用, 这样在处理后面的应用程序时可能就会报错. 因此, 链接的输入顺序也是要仔细确定的.
重定位
链接器完成符号解析之后, 就可以进行重定位:
合并区域: 对输入的各目标文件中相同类型的区域 (section) 进行合并
确定地址: 区域合并后, 为所有指令和已定义的符号确定运行时的内存地址
更新引用: 将符号引用定位到正确的地址
链接器不会通过扫描所有区域来找到需要重定位的符号引用, 而是通过汇编器给出的重定位条目 (relocation entry, 存放在 .rel.text 和 .rel.data 中). 每个重定位条目包含了符号引用在区域中的偏移量, 以及对应的符号. 链接器只需要遍历这些条目, 再根据区域的地址和符号的地址作一些基本运算就好了.
可执行的目标文件
ELF 格式下, 可执行的目标文件内部划分如下:
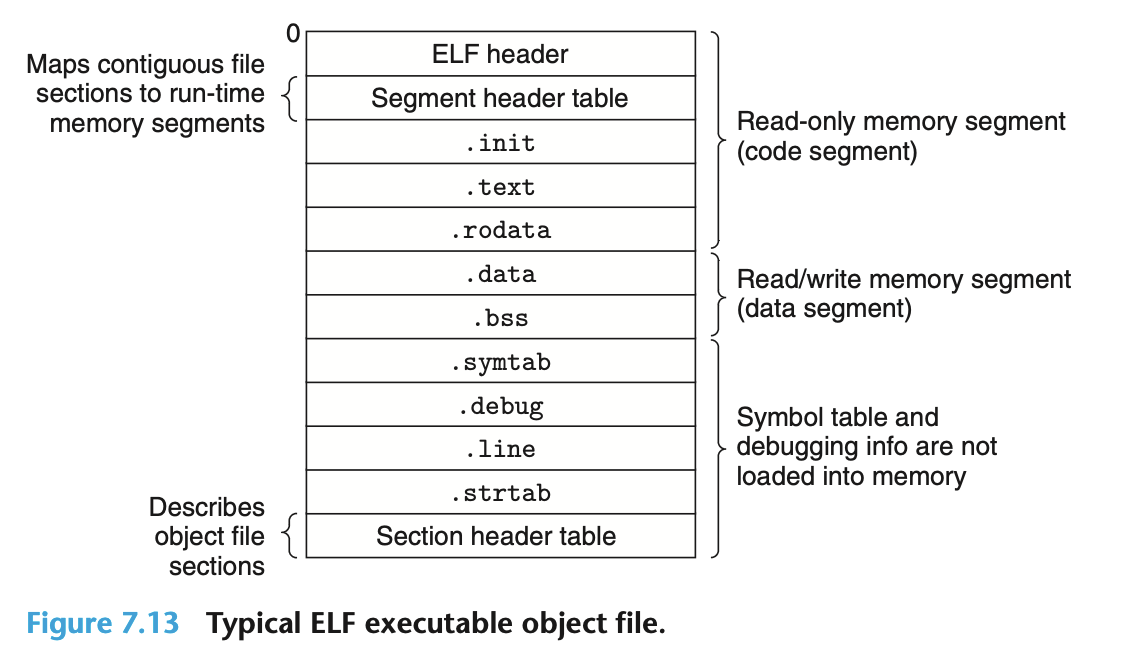
ELF header 包含了该目标文件的格式信息, 以及程序的入口点 (entry point), 即第一条指令的地址.
装载
装载是指 OS 在正式运行应用程序之前, 将可执行目标文件中的代码和数据拷贝到内存.
对应的内存结构如下:
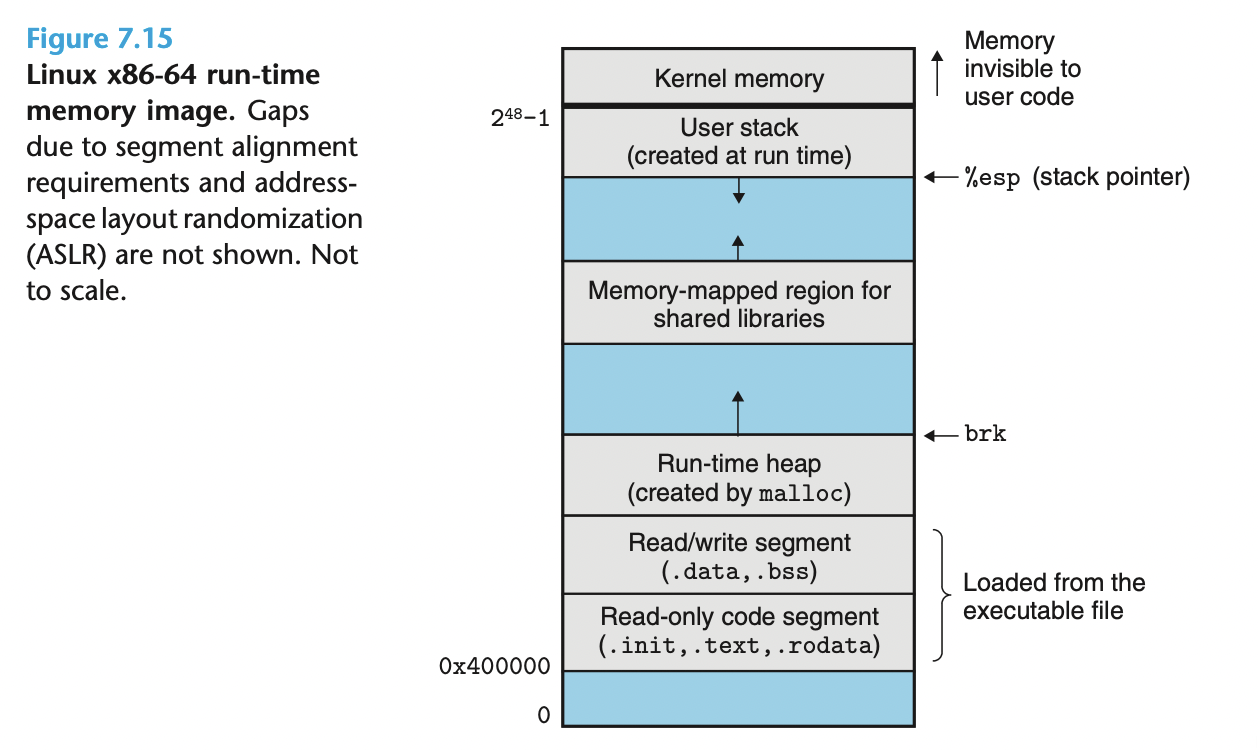
程序在运行之初 (发起 execve 系统调用) 并不会将可执行目标文件的所有代码和数据拷贝到内存中, 而是建立内存映射 (见虚拟内存), 由操作系统按需加载.
共享的目标文件
静态库的缺点是, 更新后需要再次链接, 并且对于一些常见的库 (如标准 I/O), 会在内存中产生冗余.
共享库 (shared library) 则克服了这些缺陷, 能在运行时被装载进内存的任意地址, 与应用程序进行动态链接. 在 Linux 中, 共享库以 .so 作为后缀; 在 Windows 中, 共享库被称为 DLLs (dynamic link libraries).
共享体现在两个方面:
从文件系统的角度看, 特定的库只有一个
.so文件, 不会以任何形式拷贝或嵌入到其他文件中从内存管理的角度看, 单个共享库的
.text区域可以被多个程序映射 (见 虚拟内存)
动态链接
链接命令中的 -shared 表示输出一个共享的目标文件, -fpic 指的是位置独立代码, 后面会介绍:
# 生成共享库 -> libvector.so
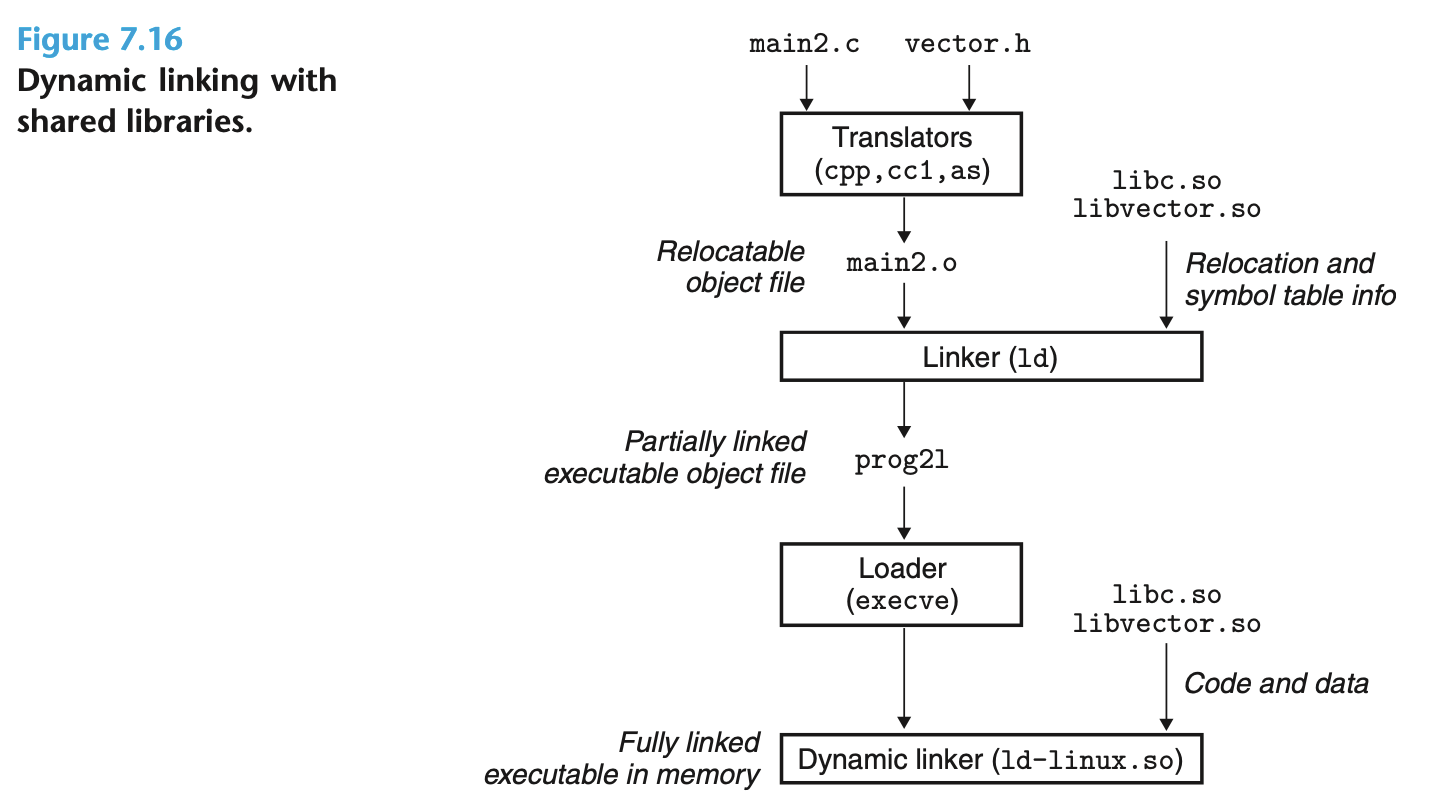
gcc -shared -fpic -o libvector.so addvec.c multivec.c动态链接的基本思想其实是将整个链接过程分成两阶段:
第一阶段, 在生成可执行目标文件的时候, 只生成共享库的符号表信息, 不拷贝其中的代码和数据.
第二阶段, 在运行时链接代码和数据, 这部分工作由系统的动态链接器 (ld-linux.so) 完成, 进行重定位:
对共享库 (libc.so, libvector.so) 的代码和数据进行重定位
对应用程序 (prog2l) 对共享库的符号引用进行重定位
动态链接还有另外一种情况, 那就是应用程序在运行时要求动态链接器装载并链接任意的共享库, 这一行为在编译期是不可知的. 典型场景如: 自动链接最新版本的库, Web 服务的动态加载, 以及 Java 中的本地接口 (JNI).
Linux 为应用程序提供了 dlopen 接口进行这种"完全"的动态链接:

装载并链接成功后, 可以通过 dlsym 接口访问其中的符号 (比如函数, 返回的是一个函数指针):
void *handle;
void (*addvec)(int *, int *, int *, int);
handle = dlopen("./libvector.so", RTLD_LAZY);
addvec = dlsym(handle, "addvec");
addvec(x, y, z, 2);
// 省略了错误处理位置独立代码 (PIC)
位置独立代码 (Position-Independent-Code) 是指不用考虑重定位的代码, 也就是可以被装载到任意位置的内存中.
共享库必须满足 PIC 性质.
编译器在生成 PIC 引用的时候, 会借助全局偏移表 (Global Offset Table, GOT), 记录每个全局变量的偏移值, 并且令代码段中的指令和 GOT 的记录有一个 (在运行时) 固定的距离, 这样就实现了位置独立.
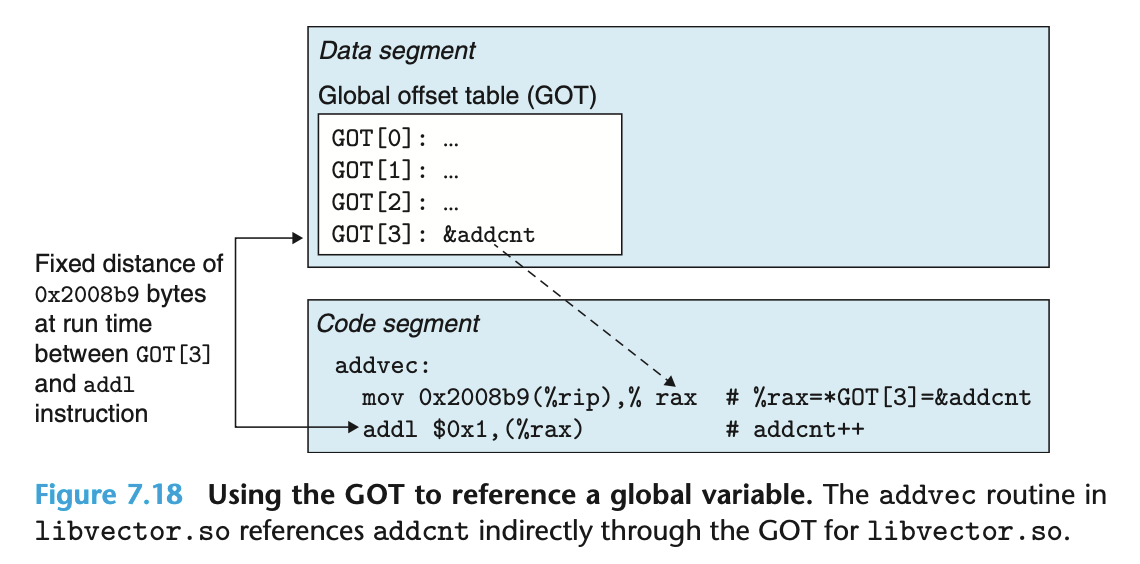
对于函数, 编译器会通过过程链接表 (Procedure Linkage Table, PLT), 结合 GOT 来实现懒绑定 (lazy binding).
库插入
库插入 (interpositioning) 是指截断对共享库函数的调用, 转而执行自己的代码, 本质是对原来的函数进行包装, 这与设计模式中的装饰器模式、面向切面编程十分类似.
库插入可以发生在编译期、链接期或运行期, 对应不同的机制.
Make
http://makefiletutorial.foofun.cn/
Make 工具最主要的功能是通过 Makefile 文件来描述源程序之间的相互关系, 并自动维护编译工作.
Makefile 文件需要说明各个源文件的编译和链接命令, 并通过 : 定义源文件之间的依赖关系.
Makefile 的基本构成是一组规则:
targets: prerequisites # rule 1
commandMake 通过检查目标与依赖项的当前时间戳, 来确定目标是否最新.